数据获取
虽说知乎有个“阅读”的话题,但是我看了一下里面的问题不全是推荐书的,若是都爬取下来可能80%的数据都是与书籍推荐无关的。
所以我直接知乎搜索“书”,选取了回答热度较高的6个问题:
点击“检查”网页,不断往下拉,
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
我们可以在XHR找到明显带有“answer”字样的链接:
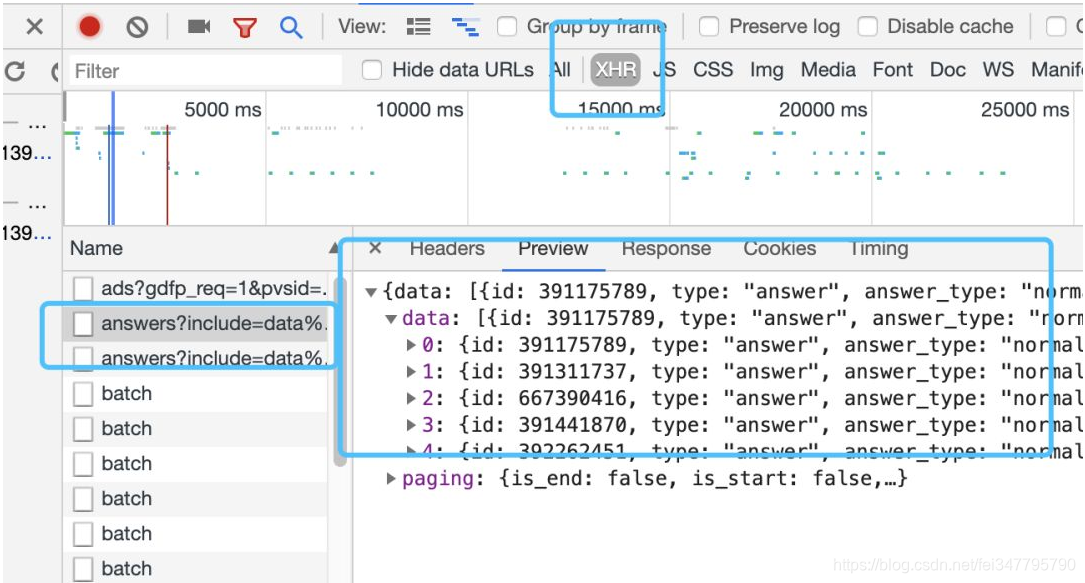
多看几个链接就能找到规律啦,
(offset:0,5,15,20……)
挑自己感兴趣的字段就能“咻咻咻”爬下来了,
其他5个问题如法炮制,得到以下:

总共获取9674个回答,基本字段如下:
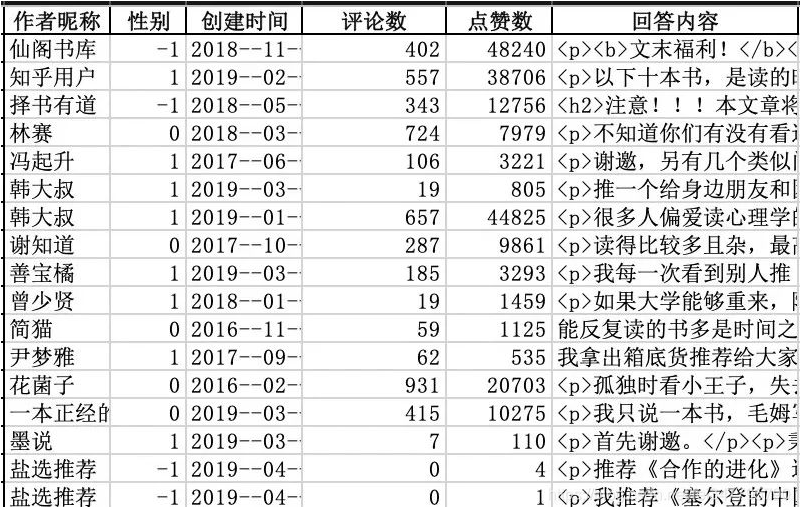
数据清洗
以前总觉得爬数据最难,只要爬下来了,一切好说!想怎么处理怎么处理,想怎么分析怎么分析。
但是这次,爬虫的主要目的是列出一个高频出现的书籍清单,大家的答案有言简意赅的。
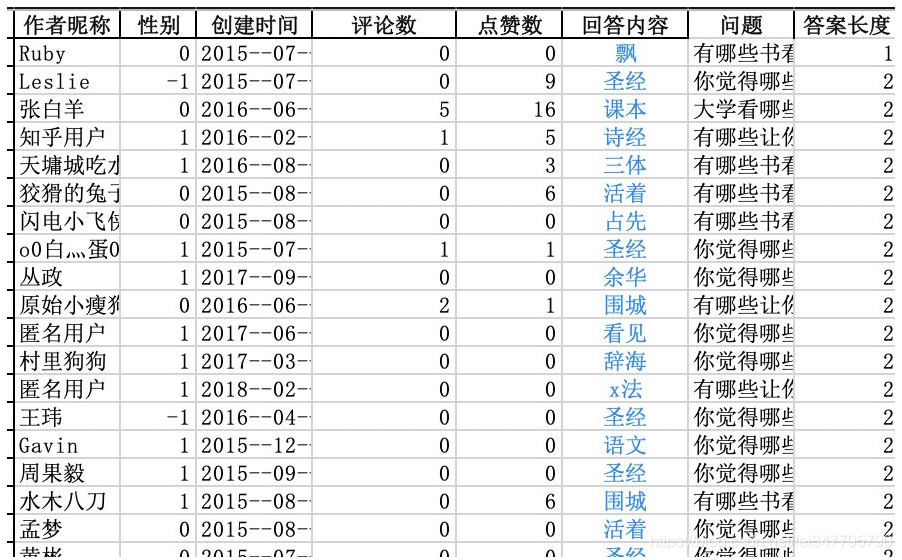
也有这样,推荐语(废话)一大堆的:
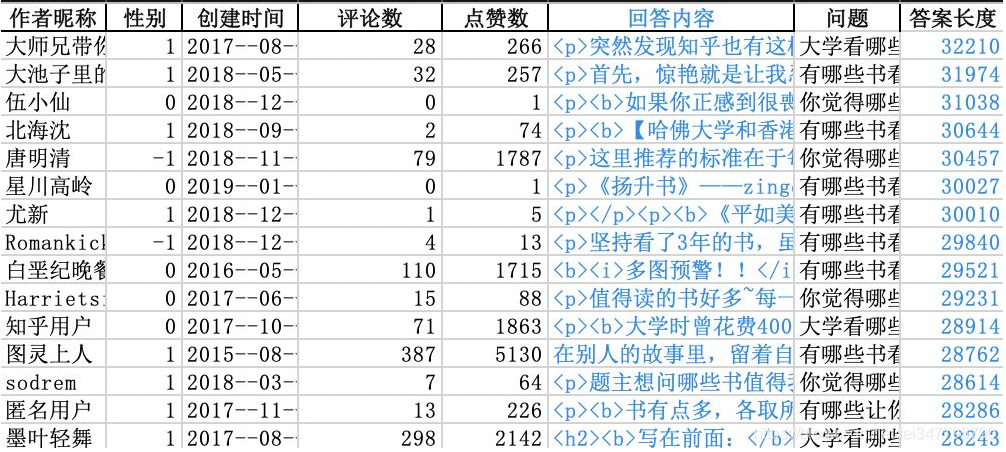
你瞧瞧,回答字数最多的可有3万多字呢!研究爬虫大概花了我一个小时,但是怎么分析这些答案让我头痛了三个晚上!先看一下主要的问题:
-
很多答案没有带书名号,因此不能简单地用正则表达式;
-
知友们回答的时候会出现书名打错(“一句话顶一万句”),还有书名简写或表达方式不同的情况(比如,关于哈利波特系列书籍的说法就有11种……);
-
最重要的是,我还不具有“看到一个词或一句话就分辨出哪些是书名哪些不是”的能力。我自己都不知道,我怎么让Python判断提取呢……
我也曾想过干脆只用《》来正则匹配内容,结果发现:
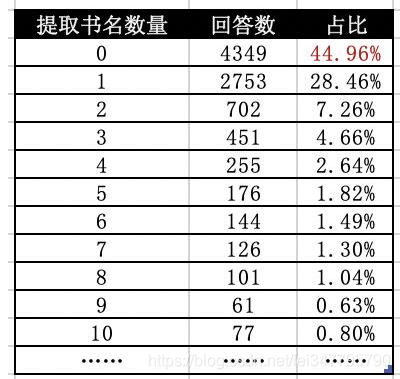
44.96%的用户回答问题的时候非常不规范,他们在回答中没有有使用书名号!直接这样分析的话就相当于丢失了将近一半的数据!
除非……除非我有一个图书库,里面有所有书的书名,这样我只要遍历每个答案,如果Ta提到了这本书,就把这个书名提取出来,最后再统计分析就好啦!然而,那句话怎么说来着,想象很丰满,现实很骨感。我并没有这样的图书库。利用现有的数据,我只能勉强以另外55.04%个答案中出现的书名,进行简单处理,得到一个简陋的书名列表……

然后再对每个答案进行遍历……
个中辛酸就不提了,提了也没用。因为并不是完美的解决之道,只能勉强满足我本次爬虫的目的罢了,不过就我走过的一些坑,我还是列一下。虽然前方有很多坑,但是大家能少进一个就少进一个吧:





数据分析
在得到最终TOP书单之前,我们按照惯例看看这些答案的基本情况。
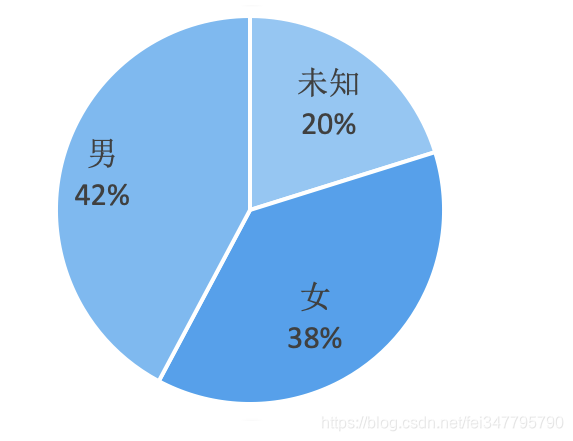
知乎后台性别显示的是0、1和-1,通过研究具体两三个用户的资料,我发现0表示女生,1表示男生,-1表示未知。
看样子这6个答案下面男生的比例略高于女生。

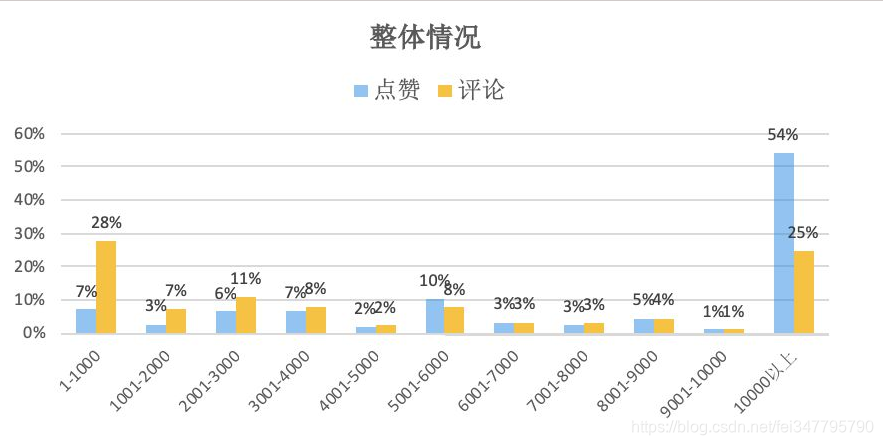
男生和女生回答问题的长度很接近,说明大家都蛮勤奋的,从互动角度来看,男生答案人均点赞数略高于女生,人均评论数却高出女生55%,可能他们的答案比较具有争议性。不过读书这种事嘛,本来就是男女老少皆宜的,因此在这种话题下区别性应该不大。
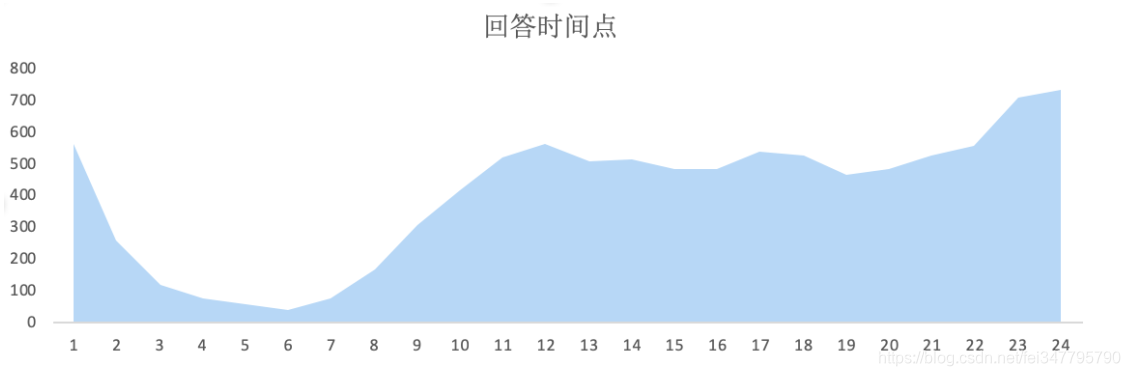
和正常(现代)人的作息很接近,大部分答案是在白天的时候提交的,其中有11%的用户在凌晨0到4点之间回答,我觉得这部分人睡前肯定没有看书。
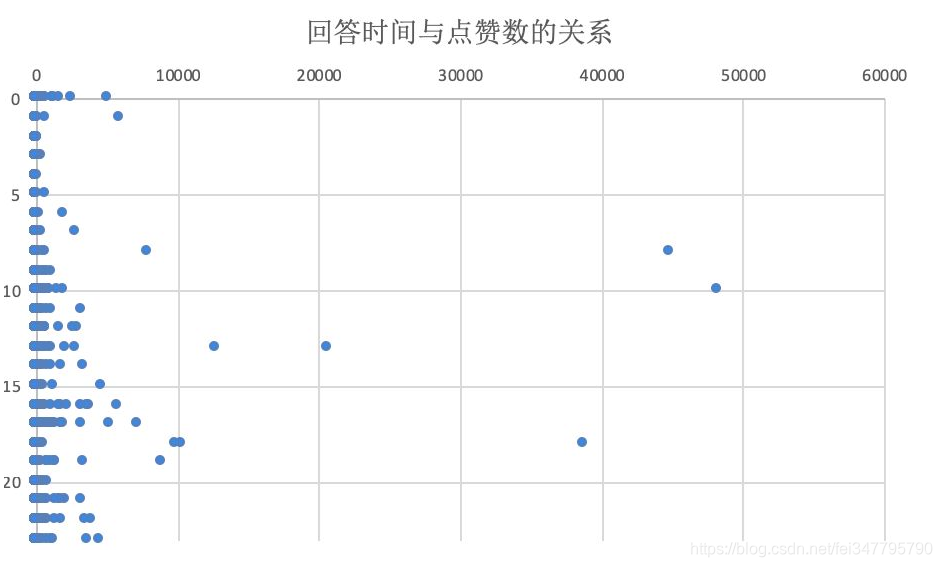
从回答时间和点赞数的散点图来看,一些高赞答案都是出现在早上8点到晚上8点之间这段时间大家精神充沛,比较容易写出高质量答案,养生Girl再次呼吁,大家一定要早睡呀!有人问睡不着怎么办?我上一段不是说了嘛(自行体会)。
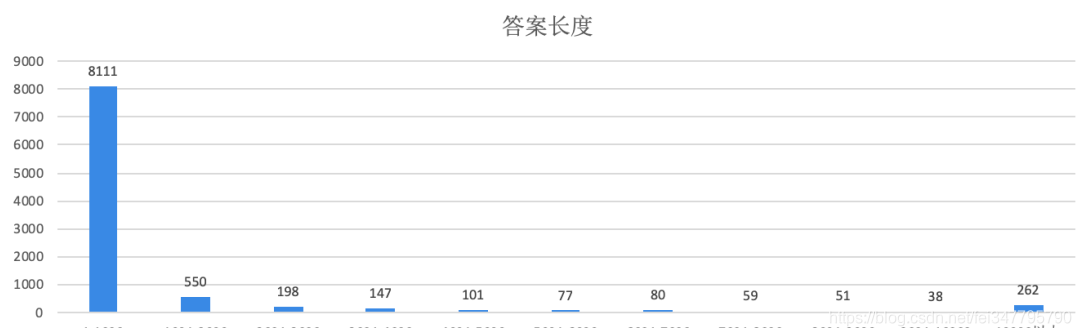
前面也提到过,答案字数最少的回答,只有一个字:飘。长度最长的有32210个字是我毕业论文长度的1.5倍。整体统计了一下,84%的答案长度在1000字以内,很符合大家碎片化阅读的习惯。然而,另外的16%用户却获得了这些答案下93%的点赞数和72%的评论数。瞧,瞧瞧(敲黑板),多么形象的二八法则实例,快做笔记同学们!
后来看看,我得到的这三天需要下载的书单(按照知友提到的频次排序):


这98本书你看过多少本呢?
有人问为什么是TOP98,不是100?因为我觉得这样看起来比较少,会更有动力“yes”所有书。