无过滤条件的LEFT JOIN
SQL中最简单形式的LEFT JOIN,是直接根据关联字段,以左表为基准,对右表进行匹配。在SELECT语句中选取的字段,如果有右表的记录(一般都是需要右表的某些记录的),取出配对成功的右表记录中对应的这个字段的值;否则,直接置NULL。这本身就是LEFT JOIN的特点:保证左表记录完整,右表只是辅助匹配。
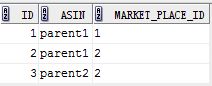
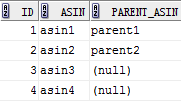
直接看例子,为了演示,准备了两张测试表test1,test2:
select * from test1
select * from test2
select t2.*,t1.market_place_id from test2 t2
left join test1 t1
on t2.parent_asin=t1.asin
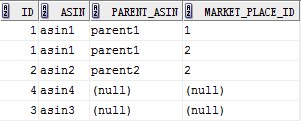
对照上面例子解释一下这个结果:以左表test2为基准,用右表test1的asin字段和test2的parent_asin字段进行匹配,取出test2的全部数据和test1的market_place_id字段。对于test2中的第一条记录,因为右表中有两条记录符合的asin='parent1',只是market_place_id不同而已(分别为1、2)。于是这两条记录都会作为符合条件的记录加入结果集。这时,虽然是以左表为基准,但是这条记录却在结果集中产生了两条对应的记录。这点要稍加注意:以左表为基准并不意味着结果集的记录数量=左表的记录数量!
再回过头来看结果集的5条记录,由ID字段可以很好的区分出每条记录是由左表的哪条记录对应产生的。这里,最后两条记录可以很好的体现出LEFT JOIN的特点。
右表有滤条件的LEFT JOIN
这里,我们忽略左表有过滤条件场景的讨论,因为在LEFT JOIN中左表作为基准表,对他的过滤直接反应在SQL的WHERE字句中,效果上也相当于单表SELECT的WHERE字句过滤,缩小左表范围后,再和右表做JOIN,没什么悬念。
但是对于右表的过滤,通常有两种主要的方式:在ON字句中加入过滤条件或者在LEFT JOIN之后的WHERE字句中加入过滤条件。对于这两种方式的对比,下面主要针对逻辑语义和实现性能上加以对比。
过滤条件在ON字句中
select t2.*,t1.market_place_id from test2 t2
left join test1 t1
on t2.parent_asin=t1.asin and t1.market_place_id='2'
上面这条SQL加上了对右表test1中market_place_id的过滤条件:只关心market_place_id为‘2’的右表记录。查询结果如下。
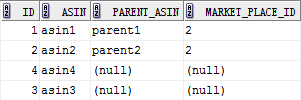
逻辑语义上,这个结果相当于右表test1首先进行了条件过滤,只剩下两条记录[(2,‘parent1’,‘2’),(3,‘parent2’,‘2’)],然后左表test2和这个过滤之后的结果集进行无过滤条件的LEFT JOIN,于是得到了上图的结果。
性能上,来看一下这条语句的执行计划截图
可以看出,T1确实先以2为标准对market_place_id做了一次过滤,然后,在外层,再做原来的LEFT JOIN。由此可以证实上面逻辑语义结果的展示,同时也可以发现,就本例而言,如果能够在market_place_id上建立index,可以直接避免内层过滤对右表进行的全表扫描,从而提高整个SQL的执行效率。下图为在market_place_id上建立index之后,同样SQL语句的执行计划:
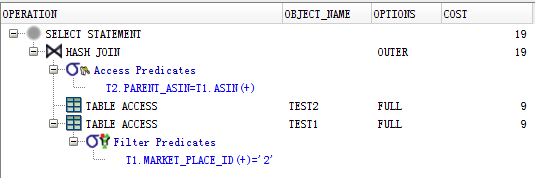
这里可以看出,原来的TABLE FULL SCAN 已经被换成了INDEX的RANGE SCAN,从而也直接导致了Oracle的优化器在最外层的Hash Join替换为了Nested Loops。(当然这个join的方式并不能说明什么问题,因为毕竟测试用的数据集太小,完全有可能在大数据集的真实情况下,优化器根据统计信息还是最终使用Hash Join算法)
过滤条件在WHERE子句中
select t2.*,t1.market_place_id from test2 t2
left join test1 t1
on t2.parent_asin=t1.asin
where t1.market_place_id='2'
上面语句的执行结果如下:
逻辑语义上,所有的market_place_id1!='2'的记录(包括NULL)全部被过滤掉了。
性能上,再来看一下这条语句的执行计划:
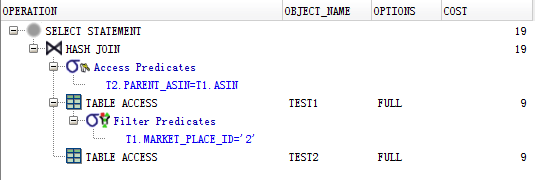
由上面的执行计划可以看出,Oracle也是首先对右表test1进行了market_place_id的过滤,但是过滤之后JOIN操作已经不是LEFT JOIN了,而是变成了普通的INNER JOIN。这就解释了为什么最后的结果集只有两条记录。
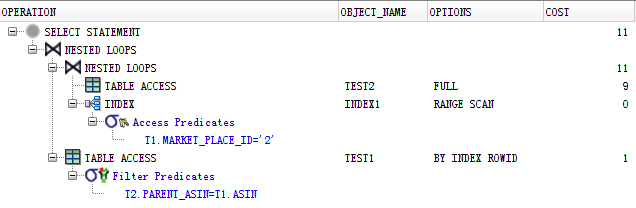
同样思路,就本例而言,在右表test的market_place_id字段上建立INDEX,同样可以达到优化SQL的目的,以下是建立INDEX之后的SQL执行计划:
结论:
在使用LEFT JOIN时,右表的限制条件,在ON和WHERE字句中出现,逻辑上的语义完全不同。
过滤条件在ON子句中出现时,不会改变原来LEFT JOIN的执行语义:以左表为基表。
过滤条件在WHERE字句中出现时,已经改变了原来LEFT JOIN的语义,相当于在最后LEFT JOIN的结果集里面再做了一次WHERE条件的过滤,所以已经丧失的LEFT JOIN的原始语义。
性能上,其实两者并没有本质的区别,扫描路径完全一致,只是对于后者,Oracle的内部实现,巧妙的将上面描述的语义转换为了通过INNER JOIN实现。这样就保证了在真正执行时还是首先进行内层过滤,缩小右表的数据集,然后进行外层INNER JOIN。
所以使用LEFT JOIN是,有需求对右表进行过滤时,要格外小心了。
备注:
以上测试使用Oracle 11g,更老版本的优化器的执行计划可能会不同。但最终语义上不会有差别。