大家好,我是小小明。今天分享两个小技巧:
Pandas的高级shift偏移
有很多玩量化的朋友经常碰到类似这样的问题:
其中有位量化大佬居然在半年后的今天又问了我一遍怎么实现这样的效果,他居然忘了我之前给他写过实现。为了避免有人再碰到类似的问题,特别写下此文。
我们知道Pandas默认的API是不支持这样的操作的,这个只能自己想办法实现。下面我借助数值索引实现这样的功能,并封装起来。
最终我们封装的方法如下:
import numpy as np
import pandas as pd
def adv_shift(s, n, na_value=pd.NA):
t = np.arange(s.shape[0])-n
t[t < 0] = s.shape[0]
tmp = s.append(pd.Series(na_value))
return pd.Series(tmp.iloc[t].values, index=s.index)
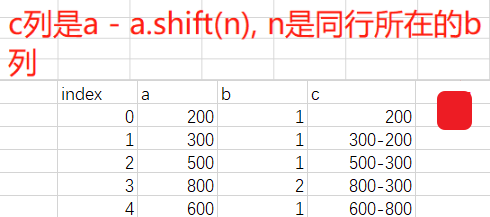
然后生成测试数据完成这个需求:
df = pd.DataFrame({"a": [200, 300, 500, 800, 600], "b": [1, 1, 1, 2, 1]})
df['c'] = df.a-adv_shift(df.a, df.b, 0)
df
| a | b | c | |
|---|---|---|---|
| 0 | 200 | 1 | 200 |
| 1 | 300 | 1 | 100 |
| 2 | 500 | 1 | 200 |
| 3 | 800 | 2 | 500 |
| 4 | 600 | 1 | -200 |
可以看到结果完全满足要求。
如果你希望直接给DataFrame对象增加高级偏移adv_shift方法,则可以这样写:
def adv_shift(self, field, n, na_value=pd.NA):
t = np.arange(self.shape[0])-self[n]
s = self[field]
t[t < 0] = s.shape[0]
tmp = s.append(pd.Series(na_value))
return pd.Series(tmp.iloc[t].values, index=s.index)
pd.DataFrame.adv_shift = adv_shift
调用方式:
df['c'] = df.a-df.adv_shift("a", "b", 0)
df
| a | b | c | |
|---|---|---|---|
| 0 | 200 | 1 | 200 |
| 1 | 300 | 1 | 100 |
| 2 | 500 | 1 | 200 |
| 3 | 800 | 2 | 500 |
| 4 | 600 | 1 | -200 |
最终结果与上述一致。
Datafream对象求差集
下面我们再看看如何求解Datafream对象的交集、并集和差集:
import pandas as pd
df1 = pd.DataFrame([[1, 11], [2, 22], [3, 33]],
columns=['a', 'b'])
df2 = pd.DataFrame([[0, 0], [1, 11], [2, 22], [4, 44]], columns=['a', 'b'])
display(df1)
display(df2)

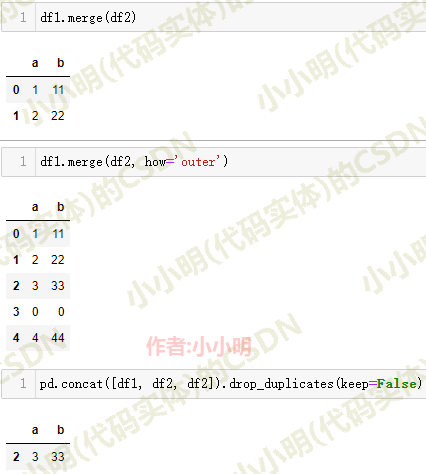
交集和并集一般的实现都是使用merge方法。
取交集:
df1.merge(df2)
去并集:
df1.merge(df2, how='outer')
关于取差集,我采用的是去重法。思路是,将df1与df2拼接,然后将重复的都去掉不保留,为了将df2全部去掉,将df2拼接两次,这样所有df2的数据都会产生重新而被删除,df1存在于与df2一致的数据也会被删除。
代码为:
pd.concat([df1, df2, df2]).drop_duplicates(keep=False)
测试结果: