写在前面: 我是「扬帆向海」,这个昵称来源于我的名字以及女朋友的名字。我热爱技术、热爱开源、热爱编程。
技术是开源的、知识是共享的。
这博客是对自己学习的一点点总结及记录,如果您对 Java、算法 感兴趣,可以关注我的动态,我们一起学习。
用知识改变命运,让我们的家人过上更好的生活。
一、认识Hashtable 与 HashMap
HashMap 和 Hashtable 都是Map接口的实现类。
Hashtable 是JDK1.0引入的,它是一个古老的实现类,在此注意Hashtable的 t 是小写的,没有遵循驼峰命名的规则,我最初学习Java的时候也想过这个问题,为了搞清楚就翻看了JDK源码:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable
源码里面也是Hashtable 而不是 HashTable,一个初级程序员都知道Java 里面需要遵循驼峰命名的规则(每个单词的首字母都应该大写),可是为啥不是HashTable,而是Hashtable。
在 stackoverflow 这个网站找到了答案:
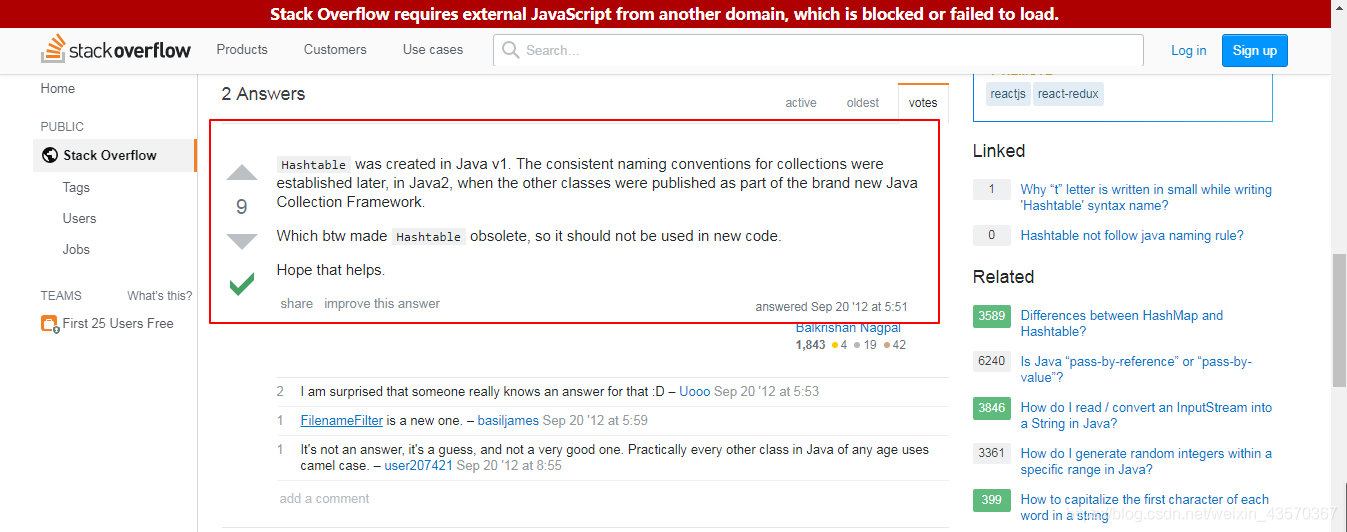
Hashtable was created in Java v1. The consistent naming conventions for collections were established later, in Java2, when the other classes were published as part of the brand new Java Collection Framework.
Which btw made Hashtable obsolete, so it should not be used in new
code.
这里所说的意思是:
- Hashtable是在Java 1中创建的。集合的一致命名约定是后来在Java2中建立的,当时其他类作为全新的Java集合框架的一部分发布。
- 哪个btw使Hashtable过时了,所以它不应该在新代码中使用。
也就是说,驼峰命名规则是Hashtable 之后出现的,后来大量的 Java程序都使用了Hashtable 这个类,因此就无法修改Hashtable为HashTable了。
HashMap Jdk源码:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
HashMap 是JDK1.2引入的。
在《Thinking in Java》这本书里面,在介绍 HashMap 的时候说,当在 get 中使用线性搜索时,执行速度会相当的慢,而这正是 HashMap 提高速度的地方。HashMap 使用了特殊的值,称作散列码,来取代对键的缓慢搜索。散列码是“相对唯一”的,用一代表对象的 int 值,它是根据某些对象的信息进行转换而生成的。hashcode() 是根据类 Object 中的方法,因此所有的java对象都能产生散列码。HashMap就是根据对象的 hashcode() 进行速度查询的,因此能够显著提高性能。
在实际开发工作中,尽量减少使用 Hashtable 类。使用 HashMap
二、Hashtable 与 HashMap 的区别
两者都实现了Map接口,底层都是哈希表结构。
- 继承的父类不同:
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。 - 线程安全性不同:
Hashtable 是线程安全的;HashMap 是线程不安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的ConcurrentHashMap - 性能不同:
Hashtable 速度慢,HashMap 速度快 - 新增元素的要求不同:
HashMap 的 key 或 value 可以为 null;Hashtable 的 key 或 value 不能为 null