我们知道在命令行敲入以下命令即可打开一个http服务器:
python -m http.server
然后就可以通过自己的IP地址来访问:
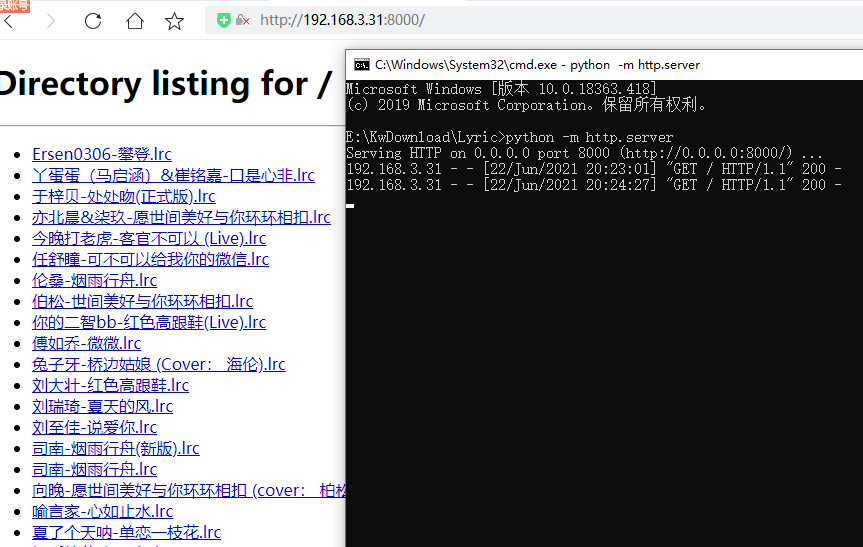
内网中的其他电脑也可以通过该IP下载你共享的文件。
现在我们希望增强该服务器的功能,增加简单的上传功能。
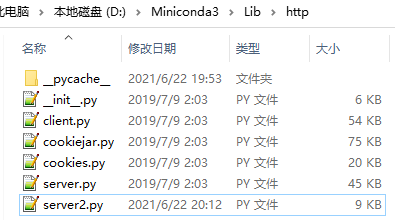
首先我们需要找到server.py文件所在的位置,一般都在python安装目录下的Lib目录下,例如我的电脑在D:\Miniconda3\Lib\http目录下,此时我们根据server.py的源码新增一个文件server2.py,代码如下:
__version__ = "0.1"
__all__ = ["SimpleHTTPRequestHandler"]
import html
import http.server
import mimetypes
import os
import posixpath
import re
import shutil
import urllib.error
import urllib.parse
import urllib.request
from io import BytesIO
class SimpleHTTPRequestHandler(http.server.BaseHTTPRequestHandler):
"""简单的http文件服务器,支持上传下载
"""
server_version = "SimpleHTTPWithUpload/" + __version__
def do_GET(self):
f = self.send_head()
if f:
self.copyfile(f, self.wfile)
f.close()
def do_HEAD(self):
f = self.send_head()
if f:
f.close()
def do_POST(self):
r, info = self.deal_post_data()
print((r, info, "by: ", self.client_address))
f = BytesIO()
f.write(b'<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">')
f.write(b"<html>\n<title>Upload Result Page</title>\n")
f.write(b"<body>\n<h2>Upload Result Page</h2>\n")
f.write(b"<hr>\n")
if r:
f.write(b"<strong>Success:</strong>")
else:
f.write(b"<strong>Failed:</strong>")
f.write(info.encode())
f.write(("<br><a href=\"%s\">back</a>" % self.headers['referer']).encode())
f.write(b"</body>\n</html>\n")
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(length))
self.end_headers()
if f:
self.copyfile(f, self.wfile)
f.close()
def deal_post_data(self):
content_type = self.headers['content-type']
if not content_type:
return (False, "Content-Type header doesn't contain boundary")
boundary = content_type.split("=")[1].encode()
remainbytes = int(self.headers['content-length'])
line = self.rfile.readline()
remainbytes -= len(line)
if not boundary in line:
return (False, "Content NOT begin with boundary")
line = self.rfile.readline()
remainbytes -= len(line)
fn = re.findall(r'Content-Disposition.*name="file"; filename="(.*)"', line.decode())
if not fn:
return (False, "Can't find out file name...")
path = self.translate_path(self.path)
fn = os.path.join(path, fn[0])
line = self.rfile.readline()
remainbytes -= len(line)
line = self.rfile.readline()
remainbytes -= len(line)
try:
out = open(fn, 'wb')
except IOError:
return (False, "Can't create file to write, do you have permission to write?")
preline = self.rfile.readline()
remainbytes -= len(preline)
while remainbytes > 0:
line = self.rfile.readline()
remainbytes -= len(line)
if boundary in line:
preline = preline[0:-1]
if preline.endswith(b'\r'):
preline = preline[0:-1]
out.write(preline)
out.close()
return (True, "File '%s' upload success!" % fn)
else:
out.write(preline)
preline = line
return (False, "Unexpect Ends of data.")
def send_head(self):
path = self.translate_path(self.path)
f = None
if os.path.isdir(path):
if not self.path.endswith('/'):
# redirect browser - doing basically what apache does
self.send_response(301)
self.send_header("Location", self.path + "/")
self.end_headers()
return None
for index in "index.html", "index.htm":
index = os.path.join(path, index)
if os.path.exists(index):
path = index
break
else:
return self.list_directory(path)
ctype = self.guess_type(path)
try:
# Always read in binary mode. Opening files in text mode may cause
# newline translations, making the actual size of the content
# transmitted *less* than the content-length!
f = open(path, 'rb')
except IOError:
self.send_error(404, "File not found")
return None
self.send_response(200)
self.send_header("Content-type", ctype)
fs = os.fstat(f.fileno())
self.send_header("Content-Length", str(fs[6]))
self.send_header("Last-Modified", self.date_time_string(fs.st_mtime))
self.end_headers()
return f
def list_directory(self, path):
try:
list = os.listdir(path)
except os.error:
self.send_error(404, "No permission to list directory")
return None
list.sort(key=lambda a: a.lower())
f = BytesIO()
displaypath = html.escape(urllib.parse.unquote(self.path))
f.write(b'<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">')
f.write(("<html>\n<title>Directory listing for %s</title>\n" % displaypath).encode())
f.write(("<body>\n<h2>Directory listing for %s</h2>\n" % displaypath).encode())
f.write(b"<hr>\n")
f.write(b"<form ENCTYPE=\"multipart/form-data\" method=\"post\">")
f.write(b"<input name=\"file\" type=\"file\"/>")
f.write(b"<input type=\"submit\" value=\"upload\"/></form>\n")
f.write(b"<hr>\n<ul>\n")
for name in list:
fullname = os.path.join(path, name)
displayname = linkname = name
# Append / for directories or @ for symbolic links
if os.path.isdir(fullname):
displayname = name + "/"
linkname = name + "/"
if os.path.islink(fullname):
displayname = name + "@"
# Note: a link to a directory displays with @ and links with /
f.write(('<li><a href="%s">%s</a>\n'
% (urllib.parse.quote(linkname), html.escape(displayname))).encode())
f.write(b"</ul>\n<hr>\n</body>\n</html>\n")
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(length))
self.end_headers()
return f
def translate_path(self, path):
path = path.split('?', 1)[0]
path = path.split('#', 1)[0]
path = posixpath.normpath(urllib.parse.unquote(path))
words = path.split('/')
words = [_f for _f in words if _f]
path = os.getcwd()
for word in words:
drive, word = os.path.splitdrive(word)
head, word = os.path.split(word)
if word in (os.curdir, os.pardir): continue
path = os.path.join(path, word)
return path
def copyfile(self, source, outputfile):
shutil.copyfileobj(source, outputfile)
def guess_type(self, path):
base, ext = posixpath.splitext(path)
if ext in self.extensions_map:
return self.extensions_map[ext]
ext = ext.lower()
if ext in self.extensions_map:
return self.extensions_map[ext]
else:
return self.extensions_map['']
if not mimetypes.inited:
mimetypes.init() # try to read system mime.types
extensions_map = mimetypes.types_map.copy()
extensions_map.update({
'': 'application/octet-stream', # Default
'.py': 'text/plain',
'.c': 'text/plain',
'.h': 'text/plain',
})
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--bind', '-b', default='', metavar='ADDRESS',
help='Specify alternate bind address '
'[default: all interfaces]')
parser.add_argument('--port', '-p', default=8000, type=int,
help='Specify alternate port [default: 8000]')
args = parser.parse_args()
http.server.test(HandlerClass=SimpleHTTPRequestHandler, port=args.port, bind=args.bind)
就像这样:
然后再运行:
python -m http.server2
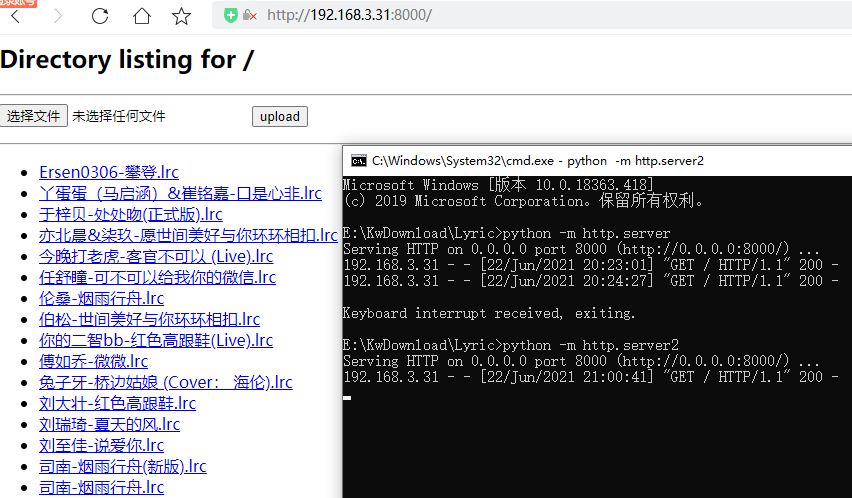
可以看到已经多了文件游览器和上传按钮。
任意上传一个文件后会出现如下提示:

点击返回或刷新页面可以重新游览文件列表。
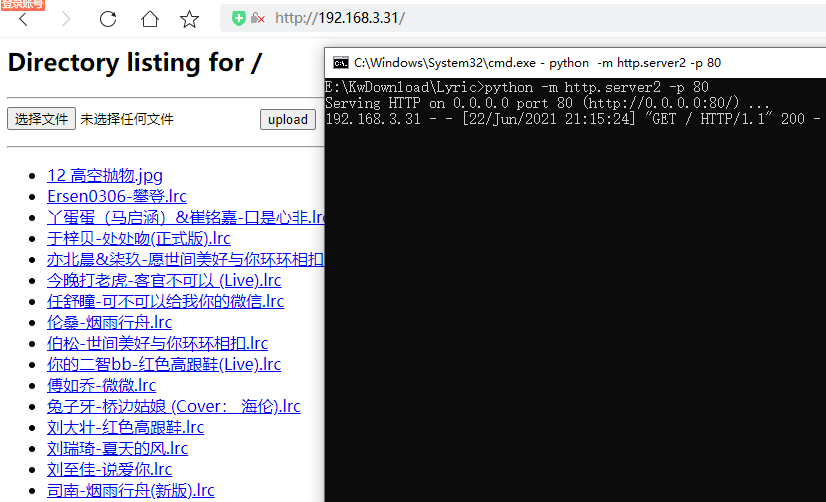
当然也支持指定端口,指定为默认的80端口时,游览器访问则无需指定端口号:
python -m http.server2 -p 80
做的非常简陋,欢迎各位大佬改进!