前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 人走茶凉csc
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
一、网页分析及爬取字段
1、爬取字段
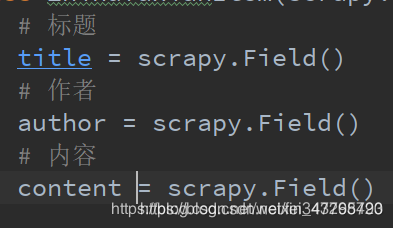
爬取字段不多,只需要三个字段即可,其中“内容”字段需要进到详情页爬取
2、网页分析
知乎发现板块为典型的ajax加载页面。
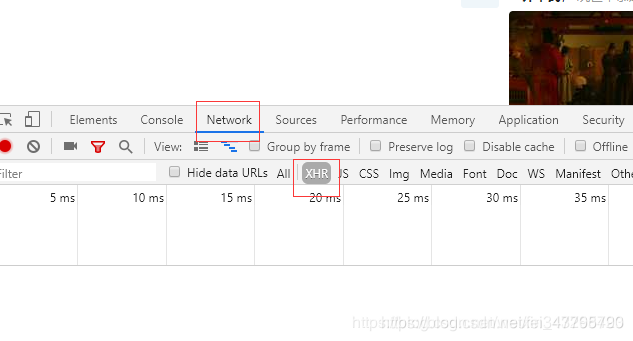
我们打开网页,右键点击检查,切换到Network界面,点击XHR,此状态下,刷新出来的均为Ajax加载条目。
接下来我们不断下拉网页

可以看到ajax加载条目不断出现。
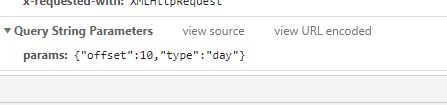
此ajax加载的params如下,我上次写的百度图片下载爬虫我们是通过构造params来实现的,在这次爬虫中我尝试使用此方法但是返回404结果所以我们通过分析ajax的url来实现。
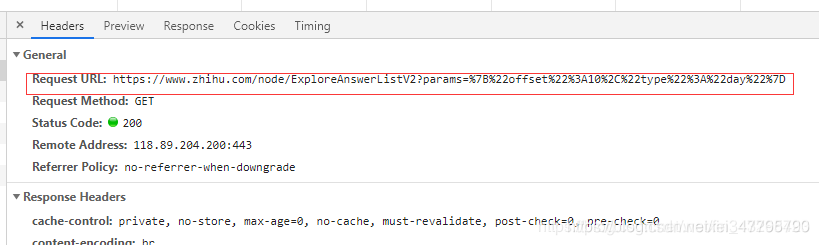
此为ajax加载出来的url
https://www.zhihu.com/node/ExploreAnswerListV2?params=%7B%22offset%22%3A10%2C%22type%22%3A%22day%22%7D
https://www.zhihu.com/node/ExploreAnswerListV2?params=%7B%22offset%22%3A15%2C%22type%22%3A%22day%22%7D
通过上面两个url分析我们可以看出此url只有一个可变参数为
所以我们只需更改此参数即可。
同时在分析网页的时候我们发现,此ajax加载上限为40页,其最后一页ajax加载网址为
https://www.zhihu.com/node/ExploreAnswerListV2?params=%7B%22offset%22%3A199%2C%22type%22%3A%22day%22%7D
好了 到目前为止,我们ajax请求的url地址我们分析结束。爬取字段部分不在分析,都是很简单的静态网页,使用xpath即可。
二、代码及解析
1、items部分
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhihufaxianItem(scrapy.Item):
# 标题
title = scrapy.Field()
# 作者
author = scrapy.Field()
# 内容
content = scrapy.Field()
建立爬取字段
2、settings部分
# -*- coding: utf-8 -*-
# Scrapy settings for zhihufaxian project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'zhihufaxian'
SPIDER_MODULES = ['zhihufaxian.spiders']
NEWSPIDER_MODULE = 'zhihufaxian.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'zhihufaxian.middlewares.ZhihufaxianSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'zhihufaxian.middlewares.ZhihufaxianDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zhihufaxian.pipelines.ZhihufaxianPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
打开itempippline部分修改user_agent即可。
3、spider
# -*- coding: utf-8 -*-
import scrapy
from zhihufaxian.items import ZhihufaxianItem
class ZhfxSpider(scrapy.Spider):
name = 'zhfx'
allowed_domains = ['zhihu.com']
start_urls = ['http://zhihu.com/']
# 知乎发现板块只能ajax加载40页
def start_requests(self):
base_url = "https://www.zhihu.com/node/ExploreAnswerListV2?"
for page in range(1, 41):
if page < 40:
params = "params=%7B%22offset%22%3A" + str(page*5) + "%2C%22type%22%3A%22day%22%7D"
else:
params = "params=%7B%22offset%22%3A" + str(199) + "%2C%22type%22%3A%22day%22%7D"
url = base_url + params
yield scrapy.Request(
url=url,
callback=self.parse
)
def parse(self, response):
list = response.xpath("//body/div")
for li in list:
item = ZhihufaxianItem()
# 标题
item["title"] = "".join(li.xpath(".//h2/a/text()").getall())
item["title"] = item["title"].replace("\n", "")
# 作者
item["author"] = "".join(li.xpath(".//div[@class='zm-item-answer-author-info']/span[1]/span[1]/a/text()").getall())
item["author"] = item["author"].replace("\n","")
details_url = "".join(li.xpath(".//div[@class='zh-summary summary clearfix']/a/@href").getall())
details_url = "https://www.zhihu.com" + details_url
yield scrapy.Request(
url=details_url,
callback=self.details,
meta={"item": item}
)
# 详情页获取content
def details(self, response):
item = response.meta["item"]
item["content"] = "".join(response.xpath("//div[@class='RichContent-inner']/span/p/text()").getall())
print(item)
首先构造start_requests方法,构造完整的url地址。然后交给parse解析,最后进到详情页拿到content字段即可。
四、总结感悟
知乎是比较好的用来练手的网站,其ajax加载出来的内容是完整的网页不是json格式的内容,省去了分析json的麻烦。
直接爬取即可。