这里的微博爬虫,我主要实现的是输入你关心的某个大 V 的微博名称,以及某条微博的相关内容片段,即可自动爬取相关该大 V 一段时间内发布的微博信息和对应微博的评论信息。
Cookie 获取
与上面的 Boss 直聘网站类似,爬取微博也需要获取响应的 cookie。
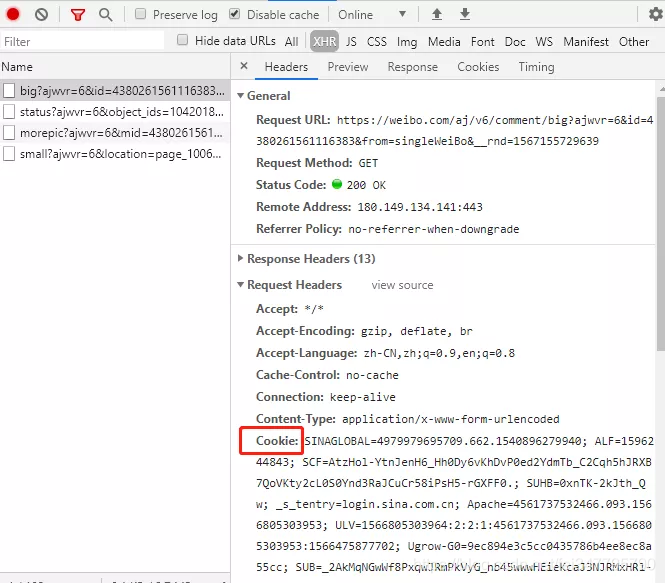
用浏览器打开微博页面,拷贝出对应的 Cookie,保存到本地。
微博搜索
既然是某位大 V,这里就肯定涉及到了搜索的事情,我们可以先来尝试下微博自带的搜索,地址如下:
s.weibo.com/user?q=林志玲
同样是先放到 Postman 里请求下,看看能不能直接访问: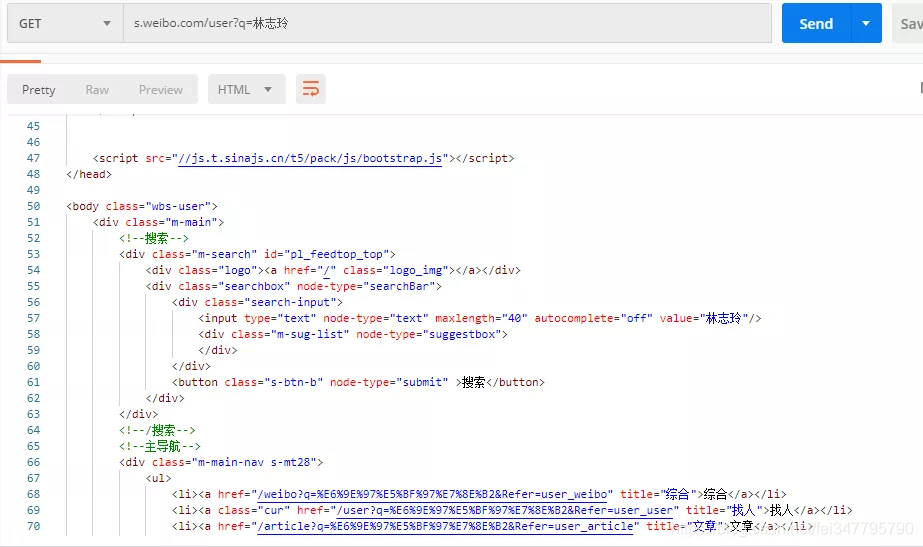
是可以的,这就省去了我们很多的麻烦。下面就是来分析并解析响应消息,拿到对我们有用的数据。
经过观察可知,这个接口返回的数据中,有一个 UID 信息,是每个微博用户的唯一 ID,我们可以拿过来留作后面使用。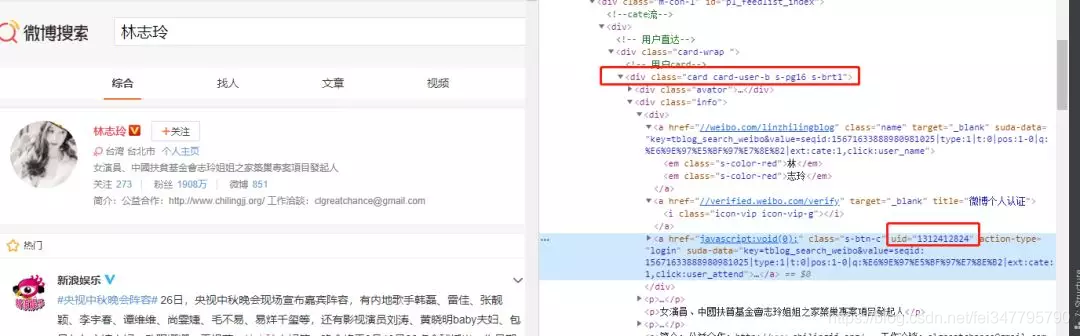
至于要如何定位到这个 UID,我也已经在图中做了标注,相信你只要简单分析下就能明白。
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
def get_uid(name):
try:
url = 'https://s.weibo.com/user?q=%s' % name
res = requests.get(url).text
content = BeautifulSoup(res, 'html.parser')
user = content.find('div', attrs={'class': 'card card-user-b s-pg16 s-brt1'})
user_info = user.find('div', attrs={'class': 'info'}).find('div')
href_list = user_info.find_all('a')
if len(href_list) == 3:
title = href_list[1].get('title')
if title == '微博个人认证':
uid = href_list[2].get('uid')
return uid
elif title == '微博会员':
uid = href_list[2].get('uid')
return uid
else:
print("There are something wrong")
return False
except:
raise
还是通过 BeautifulSoup 来定位获取元素,最后返回 UID 信息。
M 站的利用
M 站一般是指手机网页端的页面,也就是为了适配 mobile 移动端而制作的页面。一般的网站都是在原网址前面加“m.”来作为自己 M 站的地址,比如:m.baidu.com 就是百度的 M 站。
我们来打开微博的 M 站,再进入到林志玲的微博页面看看 Network 中的请求,有没有什么惊喜呢?
我们首先发现了这样一个 URL:
https://m.weibo.cn/api/container/getIndex?uid=1312412824&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%9E%97%E5%BF%97%E7%8E%B2&containerid=1005051312412824
接着继续拖动网页,发现 Network 中又有类似的 URL:
https://m.weibo.cn/api/container/getIndex?uid=1312412824&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%9E%97%E5%BF%97%E7%8E%B2&containerid=1076031312412824
URL 类似,但是第一个返回的数据是用户信息,而第二个返回的则是用户的微博信息,显然第二个 URL 是我们需要的。同样道理,把第二个 URL 放到 Postman 中,看看哪些参数是可以省略的。
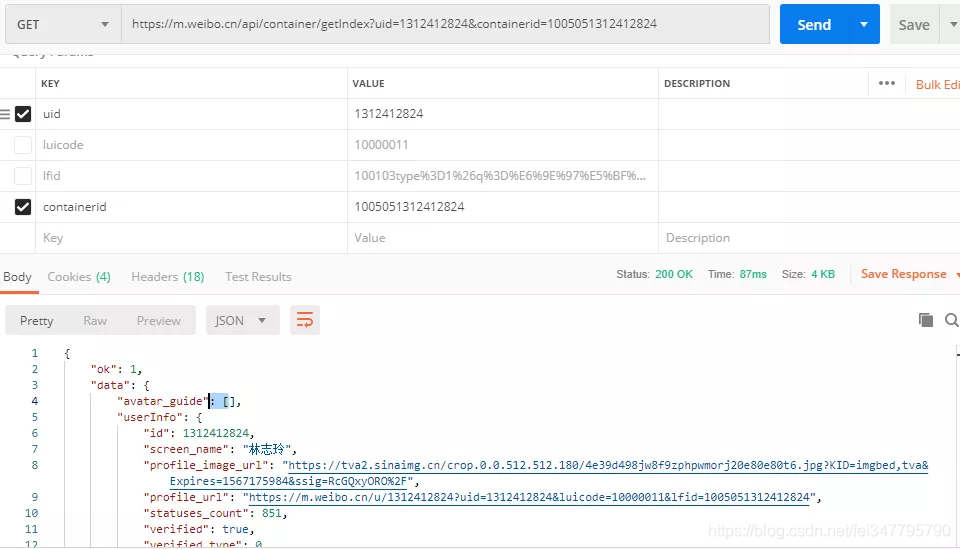
最后我们发现,只要传入正确的 containerid 信息,就能够返回对应的微博信息,可是 containerid 信息又从哪里来呢?我们刚刚获得了一个 UID 信息,现在来尝试下能不能通过这个 UID 来获取到 containerid 信息。
这里就又需要一些经验了,我可以不停的尝试给接口“m.weibo.cn/api/container/getIndex”添加不同的参数,看看它会返回些什么信息,比如常见的参数名称 type、id、value、name 等。最终,在我不懈的努力下,发现 type 和 value 的组合是成功的,可以拿到对应的 containerid 信息。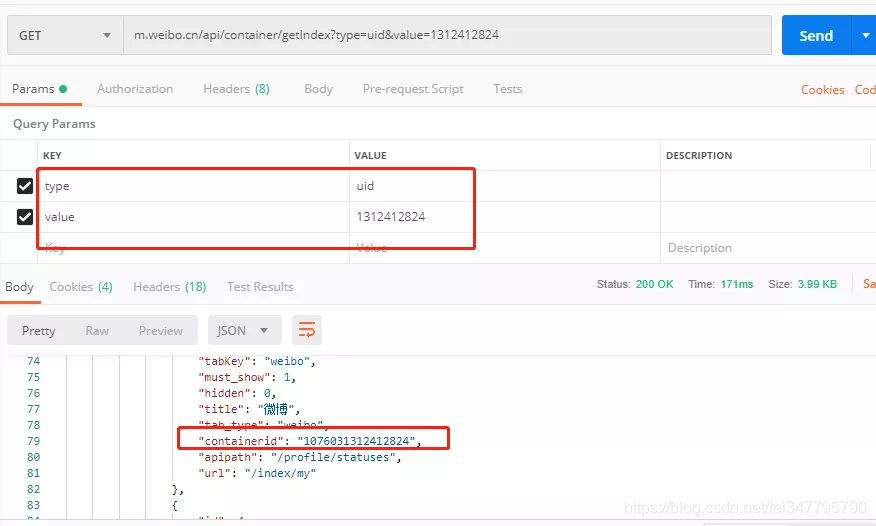
这个地方真的不有任何捷径了,只能靠尝试和经验。
现在就可以编写代码,获取对应的 containerid 了(如果你细心的话,还可以看到这个接口还返回了很多有意思的信息,可以自己尝试着抓取)。
def get_userinfo(uid):
try:
url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=%s' % uid
res = requests.get(url).json()
containerid = res['data']['tabsInfo']['tabs'][1]['containerid']
mblog_counts = res['data']['userInfo']['statuses_count']
followers_count = res['data']['userInfo']['followers_count']
userinfo = {
"containerid": containerid,
"mblog_counts": mblog_counts,
"followers_count": followers_count
}
return userinfo
except:
raise
代码里都是基本操作,不过多解释了。
拿到 containerid 信息之后,我们就可以使用上面第二个 URL 来获取微博信息了,这里还是同样的问题——分页。怎么处理分页呢,继续改造这个 getIndex 接口,继续尝试传递不同的参数给它。
这次给它传递 containerid 和 page 信息,就可以完成分页请求了。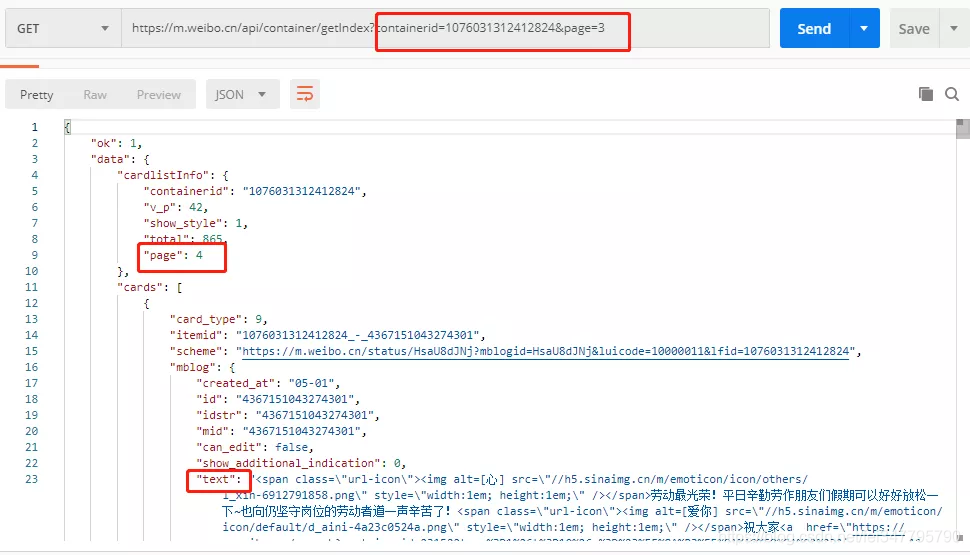
传递的 page 为 3 时,其实是获取当前新浪微博的第 4 页数据,后面我们就可以用这个 URL 来获取微博信息了。
该接口返回的是 JSON 数据,解析起来就比较方便了。
微博信息就保存在 res[‘data’][‘cards’] 下面,有评论、转发、点赞数量等信息。于是我们解析该 JSON 数据的函数就有了:
def get_blog_info(cards, i, name, page):
blog_dict = {}
if cards[i]['card_type'] == 9:
scheme = cards[i]['scheme'] # 微博地址
mblog = cards[i]['mblog']
mblog_text = mblog['text']
create_time = mblog['created_at']
mblog_id = mblog['id']
reposts_count = mblog['reposts_count'] # 转发数量
comments_count = mblog['comments_count'] # 评论数量
attitudes_count = mblog['attitudes_count'] # 点赞数量
with open(name, 'a', encoding='utf-8') as f:
f.write("----第" + str(page) + "页,第" + str(i + 1) + "条微博----" + "\n")
f.write("微博地址:" + str(scheme) + "\n" + "发布时间:" + str(create_time) + "\n"
+ "微博内容:" + mblog_text + "\n" + "点赞数:" + str(attitudes_count) + "\n"
+ "评论数:" + str(comments_count) + "\n" + "转发数:" + str(reposts_count) + "\n")
blog_dict['mblog_id'] = mblog_id
blog_dict['mblog_text'] = mblog_text
blog_dict['create_time'] = create_time
return blog_dict
else:
print("没有任何微博哦")
return False
函数参数:
- 第一个参数,接受的值为 res[‘data’][‘cards’] 的返回值,是一个字典类型数据;
- 第二个参数,是外层调用函数的循环计数器;
- 第三个参数,是要爬取的大 V 名称;
- 第四个参数,是正在爬取的页码。
最后函数返回一个字典。
搜索微博信息
我们还要实现通过微博的一些字段,来定位到某个微博,从而抓取该微博下的评论的功能。
再定义一个函数,调用上面的 get_blog_info 函数,从其返回的字典中拿到对应的微博信息,再和需要比对的我们输入的微博字段做比较,如果包含,那么就说明找到我们要的微博啦。
def get_blog_by_text(containerid, blog_text, name):
blog_list = []
page = 1
while True:
try:
url = 'https://m.weibo.cn/api/container/getIndex?containerid=%s&page=%s' % (containerid, page)
res_code = requests.get(url).status_code
if res_code == 418:
print("访问太频繁,过会再试试吧")
return False
res = requests.get(url).json()
cards = res['data']['cards']
if len(cards) > 0:
for i in range(len(cards)):
print("-----正在爬取第" + str(page) + "页,第" + str(i+1) + "条微博------")
blog_dict = get_blog_info(cards, i, name, page)
blog_list.append(blog_dict)
if blog_list is False:
break
mblog_text = blog_dict['mblog_text']
create_time = blog_dict['create_time']
if blog_text in mblog_text:
print("找到相关微博")
return blog_dict['mblog_id']
elif checkTime(create_time, config.day) is False:
print("没有找到相关微博")
return blog_list
page += 1
time.sleep(config.sleep_time)
else:
print("没有任何微博哦")
break
except:
pass
这里调用了一个工具函数 checkTime 和一个配置文件 config。
checkTime 函数定义如下:
def checkTime(inputtime, day):
try:
intime = datetime.datetime.strptime("2019-" + inputtime, '%Y-%m-%d')
except:
return "时间转换失败"
now = datetime.datetime.now()
n_days = now - intime
days = n_days.days
if days < day:
return True
else:
return False
定义这个函数的目的是为了限制搜索时间,比如对于 90 天以前的微博,就不再搜索了,也是提高效率。
而 config 配置文件里,则定义了一个配置项 day,来控制可以搜索的时间范围:
day = 90 # 最久抓取的微博时间,60即为只抓取两个月前到现在的微博
sleep_time = 5 # 延迟时间,建议配置5-10s
获取评论信息
对于微博评论信息的获取,要简单很多。
我们进入某一个微博页面,进入到评论区:
https://weibo.com/1312412824/HxFY84Gqb?filter=hot&root_comment_id=0&type=comment#_rnd1567155548217
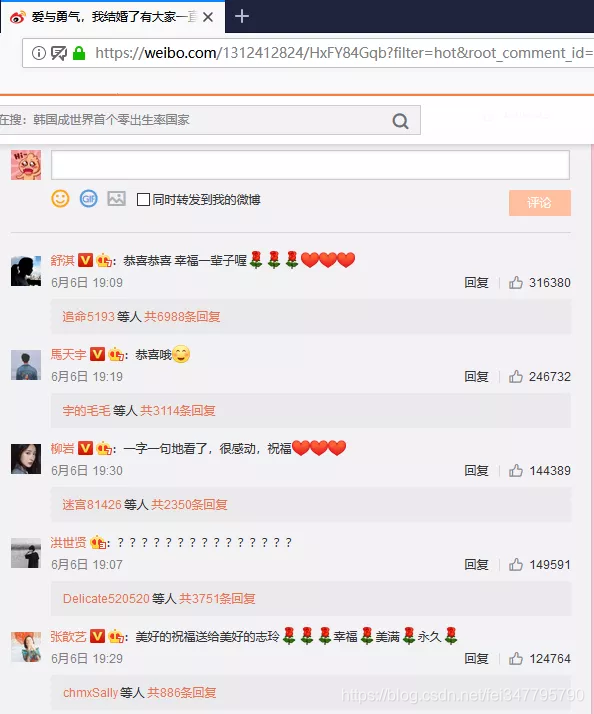
从 Network 中可以拿到一个请求 URL:
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4380261561116383&from=singleWeiBo&__rnd=1567155729639
同样使用 Postman 进行 URL 精简和分页处理,可以得到最后的 URL 为:
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=%s&page=%s
id 就是要抓取评论的微博对应的 id,我们已经在上面的接口中拿到了;
page 就是请求页数。
获取评论及保存数据代码:
def get_comment(self, mblog_id, page):
comment = []
for i in range(0, page):
print("-----正在爬取第" + str(i) + "页评论")
url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id=%s&page=%s' % (mblog_id, i)
req = requests.get(url, headers=self.headers).text
html = json.loads(req)['data']['html']
content = BeautifulSoup(html, "html.parser")
comment_text = content.find_all('div', attrs={'class': 'WB_text'})
for c in comment_text:
_text = c.text.split(":")[1]
comment.append(_text)
time.sleep(config.sleep_time)
return comment
def download_comment(self, comment):
comment_pd = pd.DataFrame(columns=['comment'], data=comment)
timestamp = str(int(time.time()))
comment_pd.to_csv(timestamp + 'comment.csv', encoding='utf-8')
定义运行函数
最后,我们开始定义运行函数,把需要用户输入的相关信息都从运行函数中获取并传递给后面的逻辑函数中。
from weibo_spider import WeiBo
from config import headers
def main(name, spider_type, text, page, iscomment, comment_page):
print("开始...")
weibo = WeiBo(name, headers)
...
if __name__ == '__main__':
target_name = input("type the name: ")
spider_type = input("type spider type(Text or Page): ")
text = "你好"
page_count = 10
iscomment = "No"
comment_page_count = 100
while spider_type not in ("Text", "text", "Page", "page"):
spider_type = input("type spider type(Text or Page): ")
...
通过 input 函数接受用户输入信息,再判断程序执行。
爬虫类与工具集
最后再来看下程序中的 WeiBo 爬虫类的定义:
class WeiBo(object):
def __init__(self, name, headers):
self.name = name
self.headers = headers
def get_uid(self): # 获取用户的 UID
...
def get_userinfo(self, uid): # 获取用户信息,包括 containerid
...
def get_blog_by_page(self, containerid, page, name): # 获取 page 页的微博信息
...
def get_blog_by_text(self, containerid, blog_text, name): # 一个简单的搜索功能,根据输入的内容查找对应的微博
...
def get_comment(self, mblog_id, page): # 与上个函数配合使用,用于获取某个微博的评论
...
def download_comment(self, comment): # 下载评论
...
在类的初始化函数中,传入需要爬取的大 V 名称和我们准备好的 headers(cookie),然后把上面写好的函数写道该类下,后面该类的实例 weibo 就能够调用这些函数了。
对于工具集,就是抽象出来的一些逻辑处理:
import datetime
from config import day
def checkTime(inputtime, day):
...
def get_blog_info(cards, i, name, page):
...
最终程序运行示例: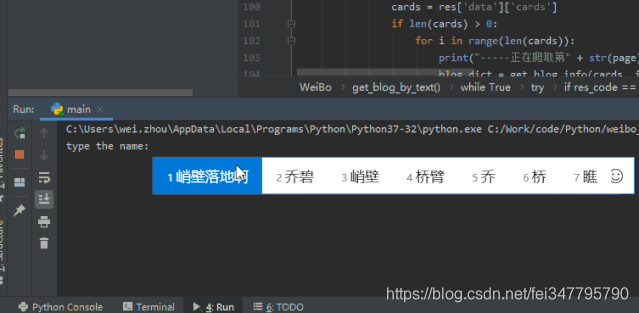
import requests
import json
from bs4 import BeautifulSoup
import pandas as pd
import time
Headers = {'Cookie': 'SINAGLOBAL=4979979695709.662.1540896279940; SUB=_2AkMrYbTuf8PxqwJRmPkVyG_nb45wwwHEieKdPUU1JRMxHRl-yT83qnI9tRB6AOGaAcavhZVIZBiCoxtgPDNVspj9jtju; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5d4hHnVEbZCn4G2L775Qe1; _s_tentry=-; Apache=1711120851984.973.1564019682028; ULV=1564019682040:7:2:1:1711120851984.973.1564019682028:1563525180101; login_sid_t=8e1b73050dedb94d4996a67f8d74e464; cross_origin_proto=SSL; Ugrow-G0=140ad66ad7317901fc818d7fd7743564; YF-V5-G0=95d69db6bf5dfdb71f82a9b7f3eb261a; WBStorage=edfd723f2928ec64|undefined; UOR=bbs.51testing.com,widget.weibo.com,www.baidu.com; wb_view_log=1366*7681; WBtopGlobal_register_version=307744aa77dd5677; YF-Page-G0=580fe01acc9791e17cca20c5fa377d00|1564363890|1564363890'}
def mayili(page):
mayili = []
for i in range(0, page):
print("page: ", i)
url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4399042567665659&page=%s' % int(i)
req = requests.get(url, headers=Headers).text
html = json.loads(req)['data']['html']
content = BeautifulSoup(html, "html.parser")
# comment = content.find_all('div', attrs={'class': 'list_li S_line1 clearfix'})
comment_text = content.find_all('div', attrs={'class': 'WB_text'})
for c in comment_text:
mayili_text = c.text.split(":")[1]
mayili.append(mayili_text)
time.sleep(5)
return mayili
def wenzhang(page):
wenzhang = []
for i in range(0, page):
print("page: ", i)
url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4399042089738682&page=%s' % int(i)
req = requests.get(url, headers=Headers).text
html = json.loads(req)['data']['html']
content = BeautifulSoup(html, "html.parser")
# comment = content.find_all('div', attrs={'class': 'list_li S_line1 clearfix'})
comment_text = content.find_all('div', attrs={'class': 'WB_text'})
for c in comment_text:
wenzhang_text = c.text.split(":")[1]
wenzhang.append(wenzhang_text)
time.sleep(5)
return wenzhang
if __name__ == '__main__':
print("start")
ma_comment = mayili(1000)
mayili_pd = pd.DataFrame(columns=['mayili_comment'], data=ma_comment)
mayili_pd.to_csv('mayili.csv', encoding='utf-8')
wen_comment = wenzhang(1000)
wenzhang_pd = pd.DataFrame(columns=['wenzhang_comment'], data=wen_comment)
wenzhang_pd.to_csv('wenzhang.csv', encoding='utf-8')
二
import jieba
import pandas as pd
from wordcloud import WordCloud
import numpy as np
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
font = r'C:\Windows\Fonts\FZSTK.TTF'
STOPWORDS = {"回复", }
def wordcloud_m():
df = pd.read_csv('mayili.csv', usecols=[1])
df_copy = df.copy()
df_copy['mayili_comment'] = df_copy['mayili_comment'].apply(lambda x: str(x).split()) # 去掉空格
df_list = df_copy.values.tolist()
comment = jieba.cut(str(df_list), cut_all=False)
words = ' '.join(comment)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue')
wc.generate(words)
wc.to_file('m.png')
def wordcloud_w():
df = pd.read_csv('wenzhang.csv', usecols=[1])
df_copy = df.copy()
df_copy['wenzhang_comment'] = df_copy['wenzhang_comment'].apply(lambda x: str(x).split()) # 去掉空格
df_list = df_copy.values.tolist()
comment = jieba.cut(str(df_list), cut_all=False)
words = ' '.join(comment)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue')
wc.generate(words)
wc.to_file('w.png')
if __name__ == '__main__':
wordcloud_m()
wordcloud_w()