前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
从 QQ 到微信,表情包一直都是中国互联网用户的「心头好」,时至今日,甚至发展到了「无表情包不聊天」的地步。
无论是正事儿还是闲侃,表情包都必不可少。聊天到一半发现表情包不够用怎么办?今天正心老师带你彻底解决这个问题!
知识点:
- requests
- css选择器
开发环境:
- 版 本:anaconda5.2.0(python3.6.5)
- 编辑器:pycharm
第三方库:
- requests
- parsel
进行网页分析
目标站点
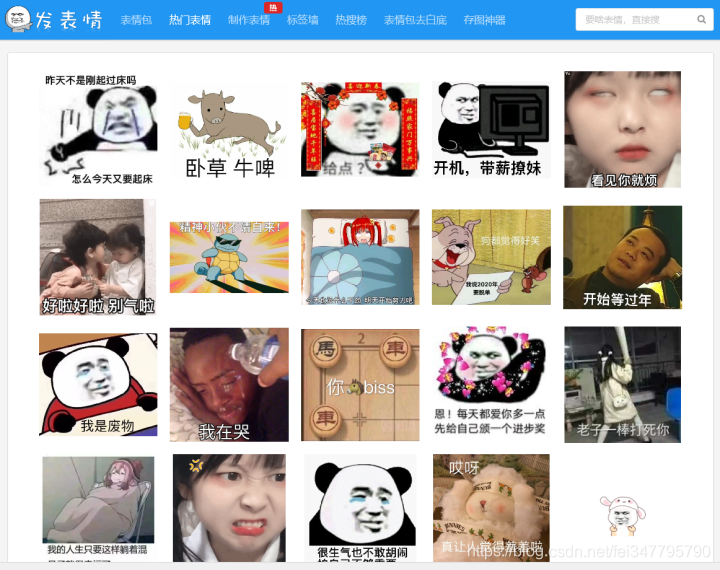
- 开发者工具的使用
- network
- element
concurrent.futures
Python3.2带来了 concurrent.futures 模块,这个模块具有线程池和进程池、管理并行编程任务、处理非确定性的执行流程、进程/线程同步等功能。
此模块由以下部分组成:
concurrent.futures.Executor: 这是一个虚拟基类,提供了异步执行的方法。submit(function, argument): 调度函数(可调用的对象)的执行,将argument作为参数传入。map(function, argument): 将argument作为参数执行函数,以 异步 的方式。shutdown(Wait=True): 发出让执行者释放所有资源的信号。concurrent.futures.Future: 其中包括函数的异步执行。Future对象是submit任务(即带有参数的functions)到executor的实例。
Executor是抽象类,可以通过子类访问,即线程或进程的 ExecutorPools 。因为,线程或进程的实例是依赖于资源的任务,所以最好以“池”的形式将他们组织在一起,作为可以重用的launcher或executor。
使用线程池
线程池或进程池是用于在程序中优化和简化线程/进程的使用。通过池,你可以提交任务给executor。池由两部分组成,一部分是内部的队列,存放着待执行的任务;另一部分是一系列的进程或线程,用于执行这些任务。池的概念主要目的是为了重用:让线程或进程在生命周期内可以多次使用。它减少了创建创建线程和进程的开销,提高了程序性能。重用不是必须的规则,但它是程序员在应用中使用池的主要原因。
current.Futures 模块提供了两种 Executor 的子类,各自独立操作一个线程池和一个进程池。这两个子类分别是:
concurrent.futures.ThreadPoolExecutor(max_workers)max_workers参数表示最多有多少个worker并行执行任务。
下面的示例代码展示了线程池和进程池的功能。这里的任务是,给一个list number_list ,包含1到10。
- 通过有5个worker的线程池执行
线程池运行
然后,我们使用了 futures.ThreadPoolExecutor 模块的线程池跑了一次::
if __name__ == "__main__":
start_time_1 = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
for item in number_list:
executor.submit(evaluate_item, item)
print("线程池计算的时间:" + str(time.time() - start_time_1), "秒")
# executor1 = concurrent.futures.ThreadPoolExecutor(max_workers=5)
# for item in number_list:
# executor1.submit(evaluate_item, item)
# executor1.shutdown()
# print("线程池计算的时间:" + str(time.time() - start_time_1), "秒")
ThreadPoolExecutor 使用线程池中的一个线程执行给定的任务。池中一共有5个线程,每一个线程从池中取得一个任务然后执行它。当任务执行完成,再从池中拿到另一个任务。
当所有的任务执行完成后,打印出执行用的时间:
print("线程池计算的时间:" + str(time.time() - start_time_1), "秒")
最终实现效果

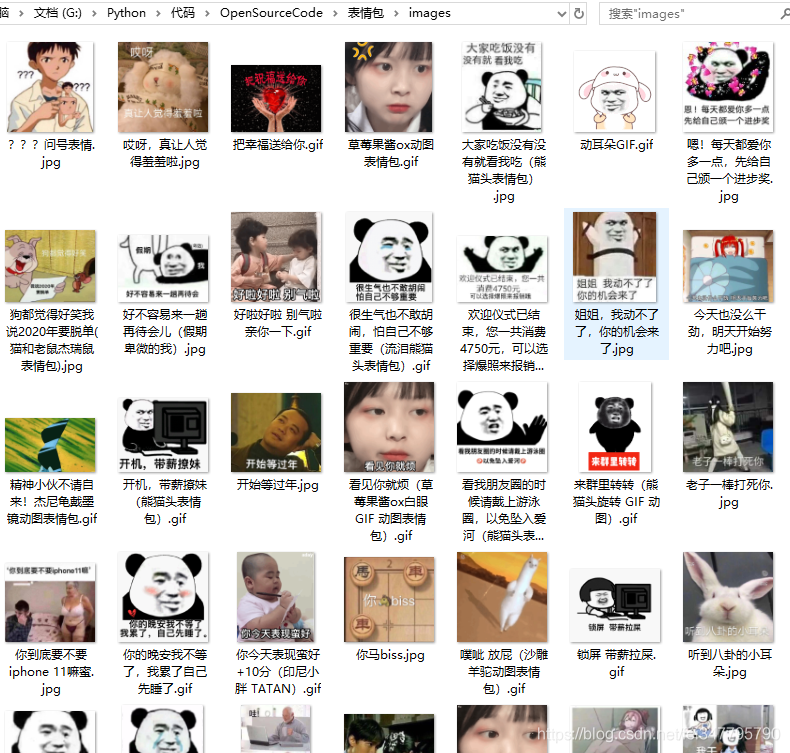
完整代码
# -*- coding: utf-8 -*-
import time
import os
import concurrent.futures
import requests
import parsel
"""图片保存文件夹"""
dir_name = 'images'
if not os.path.exists(dir_name):
os.mkdir(dir_name)
os.chdir(dir_name)
else:
os.chdir(dir_name)
def get_img_urls(url):
"""下载图片"""
response = requests.get(url)
html = response.text
# print(html)
"""解析网页中的内容"""
sel = parsel.Selector(html)
divs = sel.css('.tagbqppdiv')
for div in divs:
link = div.css('img.ui::attr(data-original)').extract_first()
name = div.css('a::attr(title)').extract_first()
yield link, name
def download_img(link: str, name: str):
"""下载并保存图片"""
try:
suffix = link.split('.')[-1]
response = requests.get(link)
with open(name + '.' + suffix, mode='wb') as f:
f.write(response.content)
except OSError:
print('文件名非法')
def main():
url = 'https://fabiaoqing.com/biaoqing/lists/page/2.html'
links = get_img_urls(url)
for link in links:
download_img(*link)
if __name__ == '__main__':
executor1 = concurrent.futures.ThreadPoolExecutor(max_workers=10)
url = 'https://fabiaoqing.com/biaoqing/lists/page/{page}.html'
links = get_img_urls(url)
start_time = time.time()
for link in links:
executor1.submit(download_img, *link)
executor1.shutdown()
# main()
print(time.time() - start_time)