前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
环境需求
基础环境沿用之前的环境,只是增加了MongoDB(非关系型数据库)和PyMongo(Python 的 MongoDB 连接库),默认我认为大家都已经安装好并启动 了MongoDB 服务。
测试爬虫效果
我这里先写一个简单的爬虫,爬取用户的关注人数和粉丝数,代码如下:
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/people/wo-he-shui-jiu-xing/following']
def parse(self, response):
# 他关注的人数
tnum = response.css("strong.NumberBoard-itemValue::text").extract()[0]
# 粉丝数
fnum = response.css("strong.NumberBoard-itemValue::text").extract()[1]
print("他关注的人数为:%s" % tnum)
print("他粉丝的人数为:%s" % fnum)
pychram中运行的结果如下:
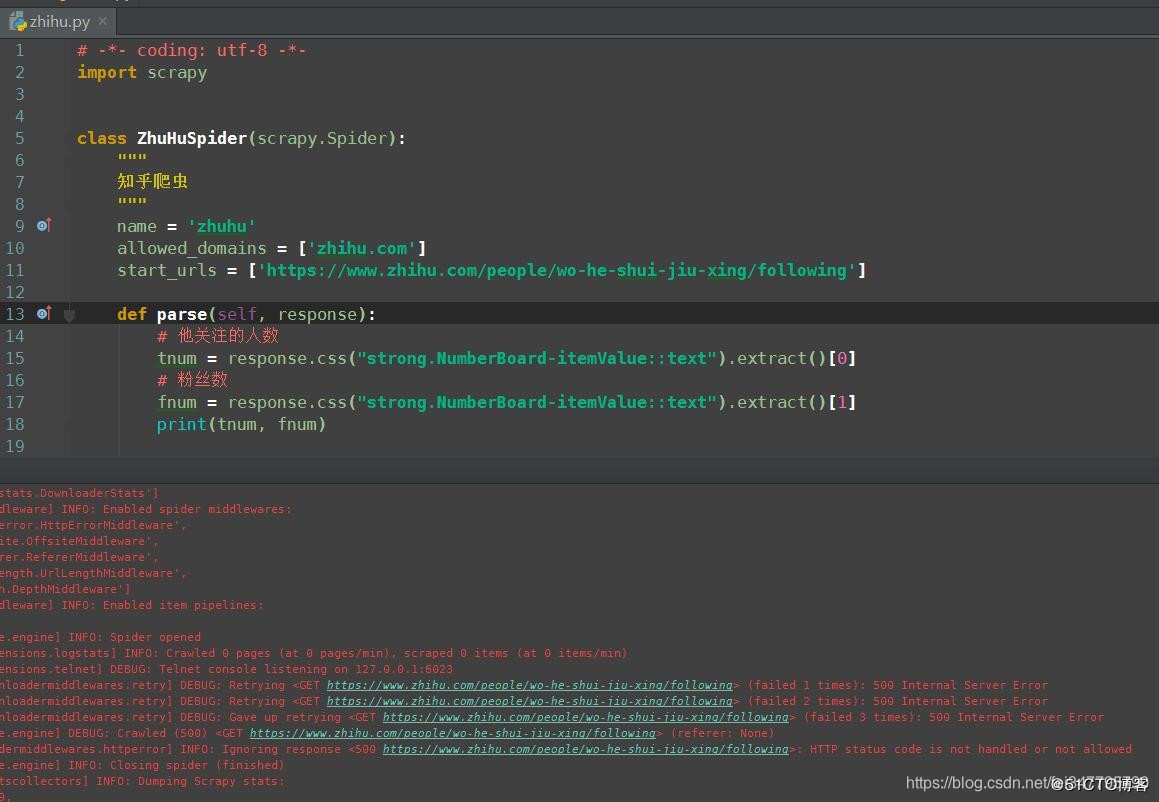
出现500错误了,我们加上headers再试试,我们直接在settings.py中设置,如下:
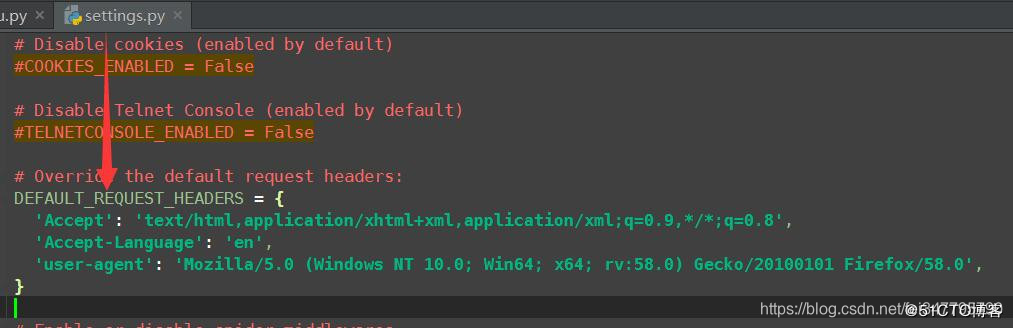
再次执行看看结果:

这次就正常获取到我们需要的信息了
爬取分析
我们就用中本聪的主页作为分析入口吧,主页如下:
https://www.zhihu.com/people/satoshi_nakamoto/following
分析用户关注列表如下: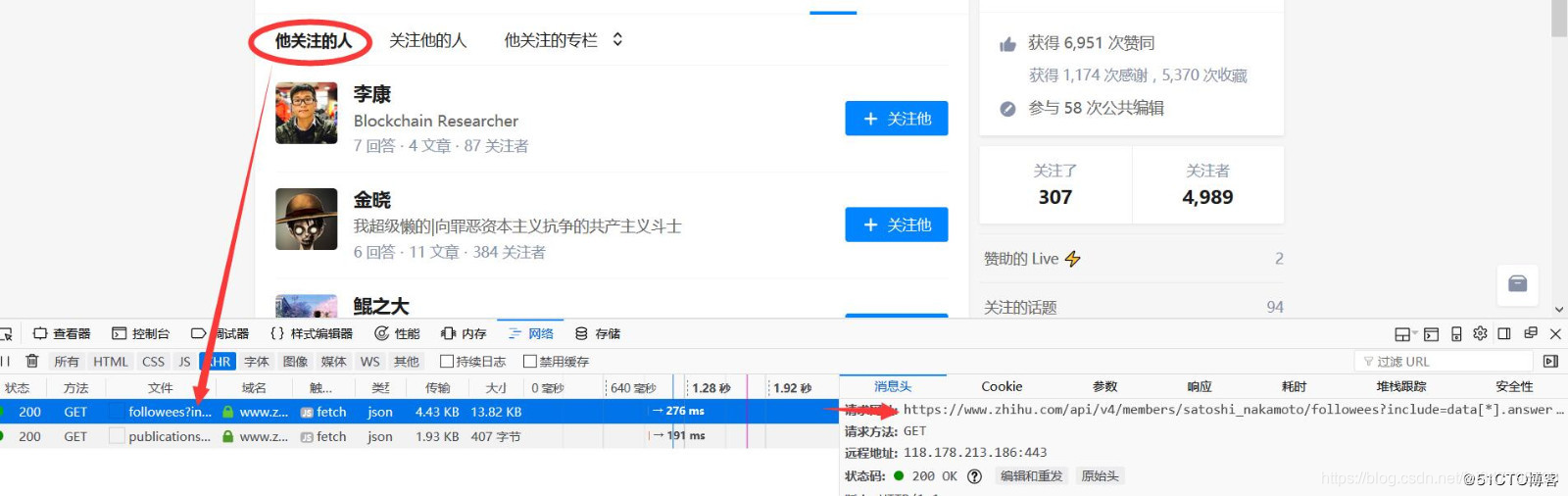
鼠标放到用户图像上,会显示详细信息如下:
这里要注意我用的是火狐浏览器,选择网络–XHR来获取信息
ajax技术的核心是XMLHttpRequest对象(简称XHR),这是由微软首先引入的一个特性,其他浏览器提供商后来都提供了相同的实现。XHR为向服务器发送请求和解析服务器响应提供了流畅的接口,能够以异步方式从服务器取得更多信息,意味着用户单击后,可以不必刷新页面也能取得新数据。
通过上面的请求我们可以获取的连接如下:
#用户详细信息
https://www.zhihu.com/api/v4/members/li-kang-65?include=allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
https://www.zhihu.com/api/v4/members/jin-xiao-94-7?include=allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
#关注的人信息
https://www.zhihu.com/api/v4/members/satoshi_nakamoto/followees?include=data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics&offset=0&limit=20
通过分析上面的链接可以看出
1.用户详细信息链接组成:https://www.zhihu.com/api/v4/members/{user}?include={include}
其中user是用户的url_token,include是allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
2.关注人信息链接组成:https://www.zhihu.com/api/v4/members/satoshi_nakamoto/followees?include={include}&offset={offset}&limit={limit}
其中include为data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics,offset为分页偏移量,limit为每页用户数量,可以通过下图看出:
第一页

第二页

第三页
开始爬取
我们还是先写一个简易的爬虫,把功能先实现,代码如下:
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
# 用户详细信息地址
user_detail = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
# 用户详细信息中的include
user_include = 'allow_message,is_followed,' \
'is_following,' \
'is_org,is_blocking,' \
'employments,' \
'answer_count,' \
'follower_count,' \
'articles_count,' \
'gender,' \
'badge[?(type=best_answerer)].topics'
# 关注的人地址
follow_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
# 关注的人include
follow_include = 'data[*].answer_count,' \
'articles_count,' \
'gender,' \
'follower_count,' \
'is_followed,' \
'is_following,' \
'badge[?(type=best_answerer)].topics'
# 初始user
start_user = 'satoshi_nakamoto'
def start_requests(self):
# 这里重新定义start_requests方法,注意这里的format用法
yield scrapy.Request(self.user_detail.format(user=self.start_user, include=self.user_include),
callback=self.parse_user)
yield scrapy.Request(self.follow_url.format(user=self.start_user, include=self.follow_include, offset=20, limit=20),
callback=self.parse_follow)
def parse_user(self, response):
print('user:%s' % response.text)
def parse_follow(self, response):
print('follow:%s' % response.text)
输出结果如下:

这里需要注意的是authorization信息一定要在headers中添加,不然会报错,authorization在headers中的形式如下: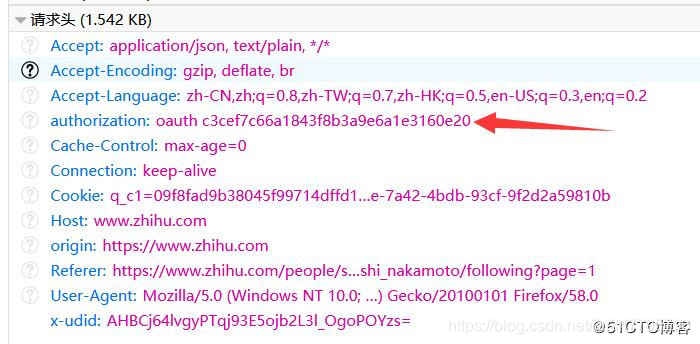
.测试发现authorization值在一段时间内是不会发生变化的,是否永久不变还有待考证。
parse_user编写
parse_user方法用来解析用户的详细数据,存储并发现此用户的关注列表,返回给parse_follow方法来处理,用户详细存储字段如下:
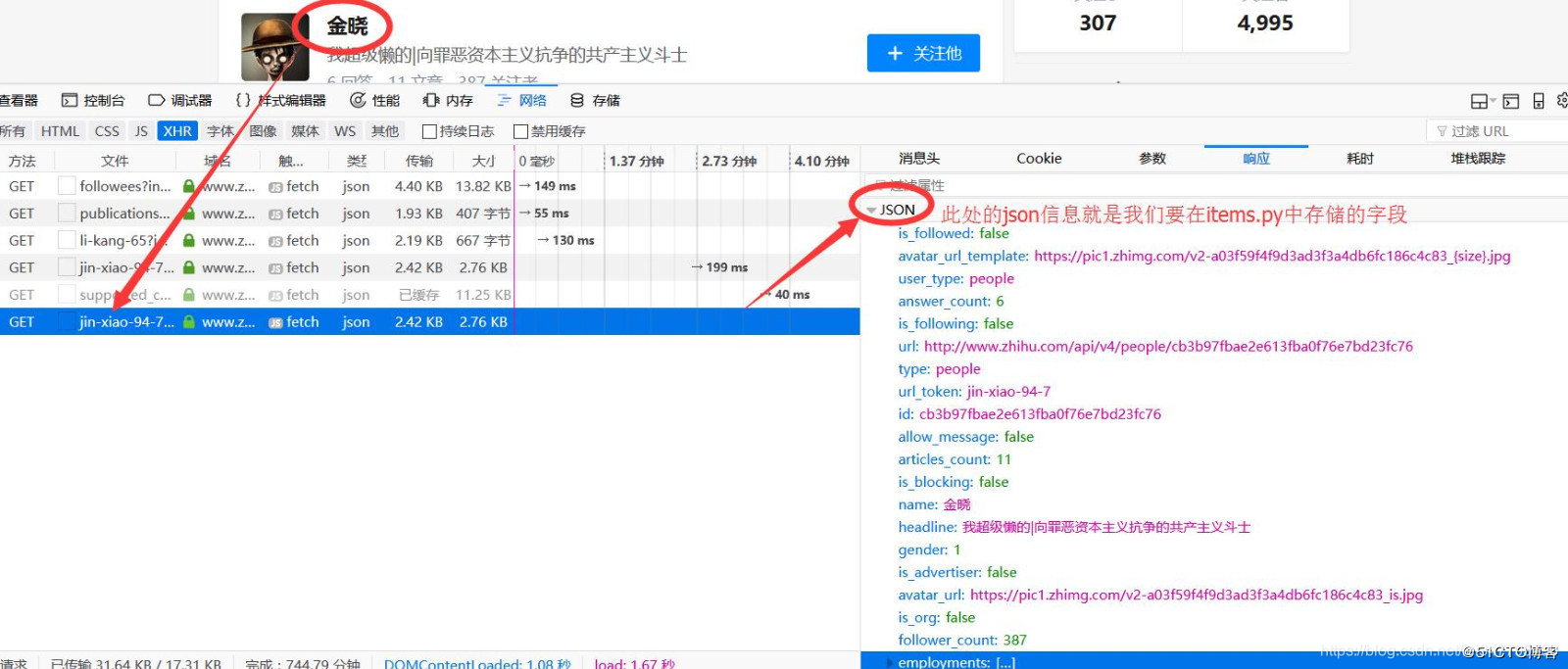
为了省事我把所有字段都添加到items.py中(如果运行spider后报错,提示字段未找到,就将那个字段添加进来即可),如下:
class UserItem(scrapy.Item):
"""
定义了响应报文中json的字段
"""
is_followed = scrapy.Field()
avatar_url_template = scrapy.Field()
user_type = scrapy.Field()
answer_count = scrapy.Field()
is_following = scrapy.Field()
url = scrapy.Field()
type = scrapy.Field()
url_token = scrapy.Field()
id = scrapy.Field()
allow_message = scrapy.Field()
articles_count = scrapy.Field()
is_blocking = scrapy.Field()
name = scrapy.Field()
headline = scrapy.Field()
gender = scrapy.Field()
avatar_url = scrapy.Field()
follower_count = scrapy.Field()
is_org = scrapy.Field()
employments = scrapy.Field()
badge = scrapy.Field()
is_advertiser = scrapy.Field()
parse_user方法代码如下:
def parse_user(self, response):
"""
解析用户详细信息方法
:param response: 获取的内容,转化为json格式
"""
# 通过json.loads方式转换为json格式
results = json.loads(response.text)
# 引入item类
item = UserItem()
# 通过循环判断字段是否存在,存在将结果存入items中
for field in item.fields:
if field in results.keys():
item[field] = results.get(field)
# 直接返回item
yield item
# 将获取的用户通过format方式组合成新的url,调用callback函数交给parse_follow方法解析
yield scrapy.Request(self.follows_url.format(user=results.get('url_token'),
include=self.follow_include, offset=0, limit=20),
callback=self.parse_follow)
parse_follow方法编写
首先也要将获取的response转换为json格式,获取关注的用户,对每一个用户继续爬取,同时也要处理分页。可以看下面两个图:
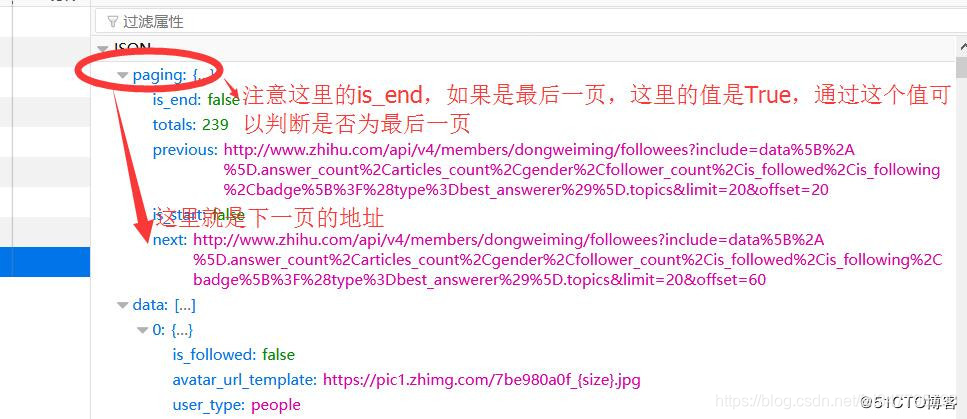
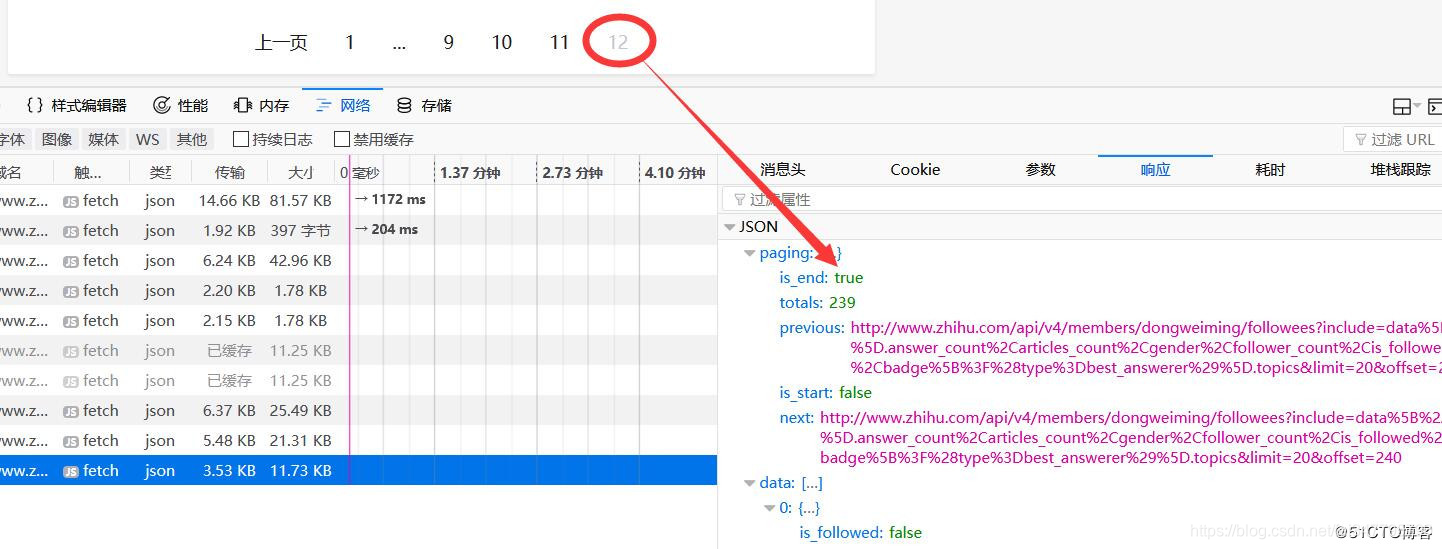
重新编写后的parse_follow方法如下:
def parse_follow(self, response):
"""
解析关注的人列表方法
"""
# 格式化response
results = json.loads(response.text)
# 判断data是否存在,如果存在就继续调用parse_user解析用户详细信息
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_detail.format(user=result.get('url_token'), include=self.user_include),
callback=self.parse_user)
# 判断paging是否存在,如果存在并且is_end参数为False,则继续爬取下一页,如果is_end为True,说明为最后一页
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parse_follow)
运行爬虫后的结果如下图:
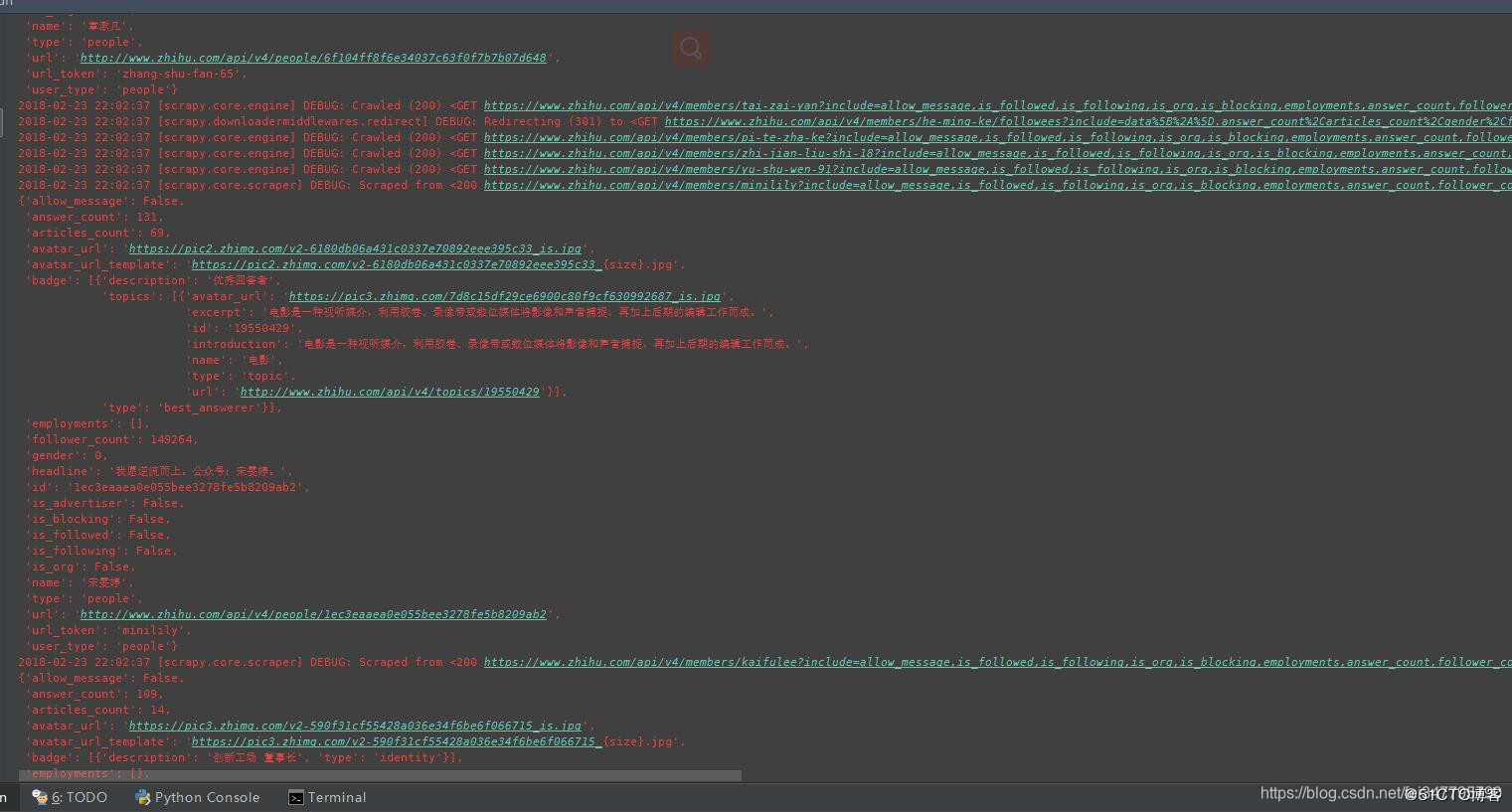
可以看到一直在获取内容。
存入mongodb
item pipeline
存储使用MongoDB,我们需要修改Item Pipeline,参照官网示例修改的代码如下:
class ZhiHuspiderPipeline(object):
"""
知乎数据存入monogodb数据库类,参考官网示例
"""
collection_name = 'user'
def __init__(self, mongo_uri, mongo_db):
"""
初始化参数
:param mongo_uri:mongo uri
:param mongo_db: db name
"""
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
# 打开连接
self.client = pymongo.MongoClient(self.mongo_uri)
# db_auth因为我的mongodb设置了认证,所以需要这两步,未设置可以注释
self.db_auth = self.client.admin
self.db_auth.authenticate("admin", "password")
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# 这里使用update方法
self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True)
return item
这里要说一说update方法,update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>, # update的查询条件,类似sql update查询内where后面的
<update>, # update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
{
upsert: <boolean>, # 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi: <boolean>, # 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新
writeConcern: <document> # 可选,抛出异常的级别。
}
)
使用update方法,如果查询数据存在的话就更新,不存在的话就插入dict(item),这样就可以去重了。
settings配置
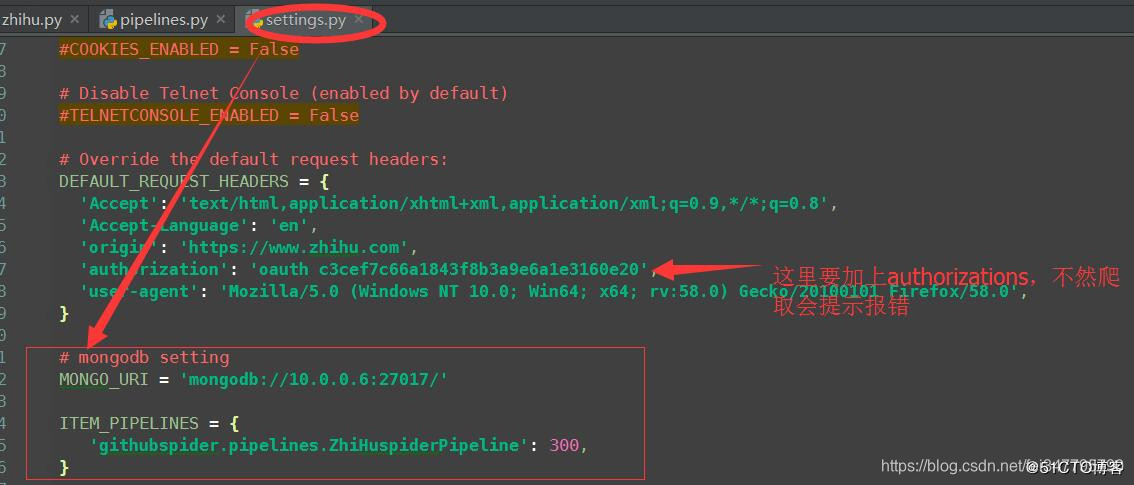
再次运行spider后结果如下: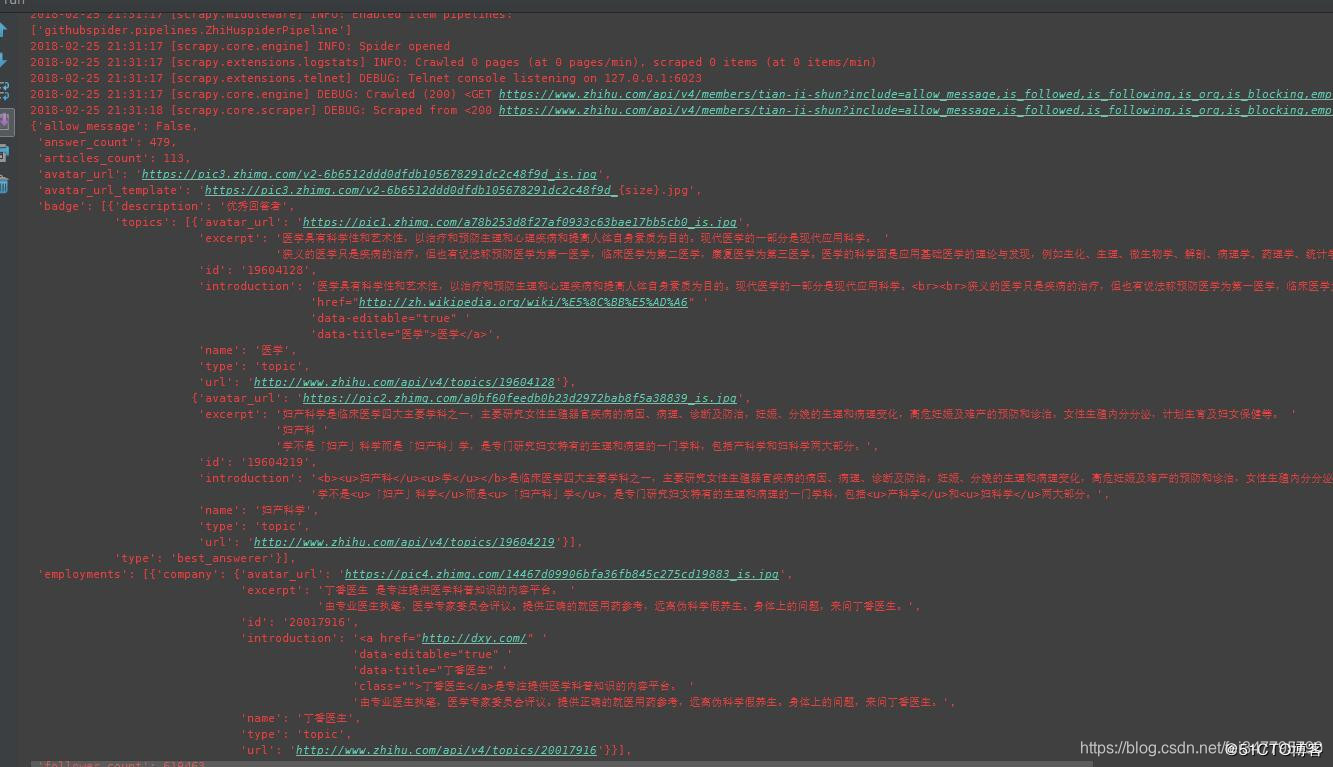
也可以看到mongodb中数据,如下: